Control Statements
awk 에 특화된 next, nextfile 구문을 제외하고 나머지는 프로그래밍 언어와 사용 방법이 같습니다.
next
현재 처리 중인 레코드를 중단하고 다음 레코드로 이동합니다.
nextfile
현재 처리 중인 파일을 중단하고 다음 파일로 이동합니다.
if-else
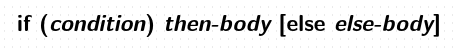
if (x % 2 == 0) if ( x == 1 )
print "x is even" print "x is 1"
else else if ( y == 2 )
print "x is odd" print "y is 2"
else if ( z == 3 )
print "z is 3"
else
print "default"
while
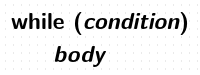
num = 1
while ( num <= 10 ) {
print num
num++
}
do-while

num = 1
do {
print num
num++
} while ( num <= 10 )
for

for (i = 1; i <= 10; i++)
print i
........................
# array 원소 추출
for (idx in arr) {
printf "index: %s, value: %s\n" ,idx ,arr[idx]
}
switch
case 문에 regex 을 사용할 수 있는데 이때는 regex 상수를 사용합니다.

$ awk '{ $ echo -e "a\nb\nc\nd" | awk '{
switch ($2) { switch($0) {
case "+" : case "a" :
res = $1 + $3 case "b" :
break print 111
case "-" : break
res = $1 - $3 case "c" :
break case "d" :
case "*" : print 222
res = $1 * $3 }
break }'
case "/" :
res = $1 / $3 ####### 실행 결과 ######
break 111
default : 111
print "Error" 222
next 222
}
print res
}'
####### 실행 결과 #######
1 + 2
3
2 * 3
6
5 -2
Error
5 - 2
3
12 / 3
4
break
while, do-while, for, switch 문에서 사용되는 것으로 반복문 실행을 중단합니다.
반복문이 중첩되어 실행되는 경우는 break 문이 위치한 안쪽 블록만 중단됩니다.
continue
while, do-while, for 문에서 사용되는 것으로 뒤에 이어지는 실행문을 skip 하고 다음 반복을 시작합니다.
exit
awk 실행을 중지하고 exit 합니다.
Quiz
JSON 데이터를 파싱 해서 pretty printing 하는 것입니다. 데이터를 기본 단위인 token 으로 분리해놓아야 shell 의 command completion 에서처럼 앞, 뒤 token 을 참조하면서 컨트롤하기 좋습니다.
$ cat json.sh
#!/usr/bin/env -S gawk -f
BEGIN {
RS="(.)" # 한 문자씩 읽어 들입니다. (getline 도 마찬가지)
if (!INDENT) INDENT = 2; # 기본 indent 크기
keyword["true"]; keyword["false"]; keyword["null"] # json 키워드
token[0]; idx = 0 # idx 변수는 token 배열의 index 로 사용
}
{ tokenize(RT) }
END {
pretty_print()
}
# { } [ ] : , 는 json 에서 사용되는 문자
function tokenize (char) {
switch (char) {
case "{" : case "}" :
case "[" : case "]" :
case ":" : case "," : token[idx++] = char; break
case "\"" : t_string(); break
case /[0-9-]/ : t_number(char); break
case /[a-z]/ : t_keyword(char); break
}
}
function t_keyword (str) {
while (getline) {
if ( RT ~ /[a-z]/ ) str = str RT
else {
if ( str in keyword ) token[idx++] = str
break
}
}
tokenize(RT)
}
function t_number (str) {
while (getline) {
if ( RT ~ /[0-9.eE+-]/ ) str = str RT
else {
if ( str ~ /^-?(0|[1-9][0-9]*)(\.[0-9]+)?([eE][+-]?[0-9]+)?$/ )
token[idx++] = str
break
}
}
tokenize(RT)
}
function t_string ( str, prev) {
while (getline) {
if ( RT != "\"" ) str = str RT
else {
if ( prev == "\\" ) str = str RT
else {
token[idx++] = "\"" str "\""
break
}
}
prev = RT
}
}
function space (depth, i, sp) {
depth = depth * INDENT
for (i=0; i < depth; i++) sp = sp " "
return sp
}
function pretty_print ( i, depth, prev, cur) {
for (i in token) {
prev = cur; cur = token[i]
switch (cur) {
case "{" :
printf (prev == ":" ? "" : "\n" space(depth)) "{"
depth++; break
case "}" :
depth--
printf (prev == "{" ? " " : "\n" space(depth)) "}"
break
case "[" :
printf (prev == ":" ? "" : "\n" space(depth)) "["
depth++; break
case "]" :
depth--
printf (prev == "[" ? " " : "\n" space(depth)) "]"
break
case "," : printf ","; break
case ":" : printf ": "; break
default :
# "%" 문자는 printf 문에서 format specifier 를 작성할 때 사용되므로
# "%" 문자가 그대로 출력되려면 "%%" 로 변경해야 합니다.
printf (prev == ":" ? "" : "\n" space(depth)) gensub(/%/,"%%","g",cur)
}
if (depth == 0) break
}
print ""
}
$ cat sample.json
{"squadName":"Super hero squad","homeTown":"Metro City","formed":2016,"secretBase":
"Super tower","active":true,"members":[{"name":"Molecule Man","age":29,"secretIdentity":
"Dan Jukes","powers":["Radiation resistance","Turning tiny","Radiation blast"]},{"name":
"Madame Uppercut","age":39,"secretIdentity":"Jane Wilson","powers":["Million tonne punch",
"Damage resistance","Superhuman reflexes"]},{"name":"Eternal Flame","age":1000000,
"secretIdentity":"Unknown","powers":["Immortality","Heat Immunity","Teleportation",
"Interdimensional travel"]}]}
$ ./json.sh sample.json
{
"squadName": "Super hero squad",
"homeTown": "Metro City",
"formed": 2016,
"secretBase": "Super tower",
"active": true,
"members": [
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes",
"powers": [
"Radiation resistance",
"Turning tiny",
"Radiation blast"
]
},
{
"name": "Madame Uppercut",
"age": 39,
"secretIdentity": "Jane Wilson",
"powers": [
"Million tonne punch",
"Damage resistance",
"Superhuman reflexes"
]
},
{
"name": "Eternal Flame",
"age": 1000000,
"secretIdentity": "Unknown",
"powers": [
"Immortality",
"Heat Immunity",
"Teleportation",
"Interdimensional travel"
]
}
]
}
RT변수를 사용하지 않고 처리하는 방법은 여기 를 참조하세요.
2 .
이번에는 검색 기능을 추가하는 것입니다.
사용할 수 있는 옵션은 -k , -s 두 가지가 있는데
-k 옵션은 전체 데이터에서 key 만 뽑아서 계층 구조로 출력합니다.
구분자는 디렉토리 경로와 같이 / 문자로 하였습니다.
-s 옵션은 검색할 때 사용하는데 앞서 출력된 key 값들 중 하나를 설정하면
해당 key 와 매칭되는 value 들을 출력합니다.
key=value 형태로 검색할 수도 있는데 이때는 매칭되는 값이 존재하는
블록 전체를 표시합니다.
$ ./json.sh -k sample.json # 전체 key 값을 출력
/squadName
/homeTown
/formed
/secretBase
/active
/members
/members/name
/members/age
/members/secretIdentity
/members/powers
/members/name
/members/age
/members/secretIdentity
/members/powers
/members/name
/members/age
/members/secretIdentity
/members/powers
# key 값이 /members/name 인 value 를 모두 출력
$ ./json.sh -s /members/name sample.json
"Molecule Man"
"Madame Uppercut"
"Eternal Flame"
# /members/name 의 value 가 "Molecule Man" 인 블록을 출력
$ ./json.sh -s /members/name="Molecule Man" sample.json
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes",
"powers": [
"Radiation resistance",
"Turning tiny",
"Radiation blast"
]
}
# shell 에서 파이프와 함께 사용할 때는 stdin 을 나타내는 "-" 를 사용하면 됩니다.
$ cat sample.json | ./json.sh -s /members/name="Molecule Man" -
코드는 처음 예제와 동일한데 검색 기능을 위해서 search 함수가 추가되고
명령 라인 인수를 처리하기 위해 BEGINFILE 블록이 추가되었습니다.
shebang 라인을 보면 gawk -f 에서 gawk -E 로 변경된 것을 볼 수 있습니다.
#!/usr/bin/env -S gawk -E
BEGIN {
RS="(.)"
INDENT = 2;
keyword["true"]; keyword["false"]; keyword["null"]
token[0] = opt1 = opt2 = ""
idx = cdx = 0
}
BEGINFILE {
if ( FILENAME ~ /^-k$|^-s$/ ) { opt1 = FILENAME; nextfile }
if ( opt1 == "-s" && opt2 == "" ) { opt2 = FILENAME; nextfile }
}
{ tokenize(RT) }
END {
if (opt1) search(); else pretty_print(0)
}
# json 데이터는 괄호 안에 괄호가 계속 이어지는 형태이기 때문에 각각의 괄호에서의
# context 를 유지하려면 recursion 을 이용하는 것이 좋습니다.
# "{" "[" 여는 괄호를 만나면 다시 자기 자신을 호출하고 "}" "]" 닫는 괄호를 만나면
# return 합니다. 자기 자신을 호출할 때는 path "/" ckey 형태로 만들어지는 누적 경로와
# key=value 검색을 위한 시작 괄호 index 번호를 context 로 유지하기 위해서
# 각각 path, sblock 매개변수로 지정합니다. 모든 token 값을 차례로 처리하기 위한
# cdx 변수는 recursion 에 상관없이 계속 증가돼야 하므로 global 변수로 지정합니다.
function search (path, sblock, ckey, key, val) {
for ( ; cdx < idx; cdx++) {
switch (token[cdx]) {
case "{" : # 블록의 시작을 나타내는 "{" "["
case "[" : # 의 현재 index 값인 cdx 를
search( path "/" ckey, cdx++) # sblock 매개변수 값으로 전달
break
case "}" :
case "]" : return
case ":" :
# ckey 는 현재 "key" : "value" 에서 quotes 을 제거한 key 부분
ckey = gensub( /^"(.*)"$/, "\\1", "g", token[cdx - 1])
# key 는 검색에 사용되는 값인데 path 에 중복되는 //, /// ..
# 이 있을경우 / 하나로 정리하여 key 변수에 대입
key = gensub( /\/{2,}/, "/", "g", path "/" ckey)
if ( opt1 == "-k" ) print key
else if ( opt1 == "-s" ) { # 검색에 사용된 key 값인 opt2 와
if ( opt2 == key ) { # key 변수값이 같을경우 다음 token
switch( token[cdx + 1] ) { # 을 조회하여 "[" or "{" 일 경우
case "[" : # pretty_print 를 이용해 블록을 출력
case "{" : pretty_print(cdx + 1); break
default : print token[cdx + 1]
}
} else {
# val 는 검색에 사용되는 값으로 quotes 을 제거해 사용
val = gensub( /^"(.*)"$/, "\\1", "g", token[cdx + 1])
# opt2 값이 key=val 와 같으면 sblock 값으로 블록을 출력
if ( opt2 == key "=" val ) pretty_print(sblock)
}
}
}
}
}
function tokenize (char) {
switch (char) {
case "{" : case "}" :
case "[" : case "]" :
case ":" : case "," : token[idx++] = char; break
case "\"" : t_string(); break
case /[0-9-]/ : t_number(char); break
case /[a-z]/ : t_keyword(char); break
}
}
function t_keyword (str) {
while (getline) {
if ( RT ~ /[a-z]/ ) str = str RT
else {
if ( str in keyword ) token[idx++] = str
break
}
}
tokenize(RT)
}
function t_number (str) {
while (getline) {
if ( RT ~ /[0-9.eE+-]/ ) str = str RT
else {
if ( str ~ /^-?(0|[1-9][0-9]*)(\.[0-9]+)?([eE][+-]?[0-9]+)?$/ )
token[idx++] = str
break
}
}
tokenize(RT)
}
function t_string ( str, prev) {
while (getline) {
if ( RT != "\"" ) str = str RT
else {
if ( prev == "\\" ) str = str RT
else {
token[idx++] = "\"" str "\""
break
}
}
prev = RT
}
}
function space (depth, i, sp) {
depth = depth * INDENT
for (i=0; i < depth; i++) sp = sp " "
return sp
}
# pretty_print 함수를 호출할 때 "{" "[" 시작 괄호의 index 번호 (token 배열에서)
# 를 인수로 전달하면 해당 블록만 프린트됩니다.
function pretty_print (start, i, depth, prev, cur) {
for (i = start; i < idx; i++) {
prev = cur; cur = token[i]
switch (cur) {
case "{" :
printf (prev == ":" ? "" : "\n" space(depth)) "{"
depth++; break
case "}" :
depth--
printf (prev == "{" ? " " : "\n" space(depth)) "}"
break
case "[" :
printf (prev == ":" ? "" : "\n" space(depth)) "["
depth++; break
case "]" :
depth--
printf (prev == "[" ? " " : "\n" space(depth)) "]"
break
case "," : printf ","; break
case ":" : printf ": "; break
default :
printf (prev == ":" ? "" : "\n" space(depth)) gensub(/%/,"%%","g",cur)
}
if (depth == 0) break
}
print ""
}
search 함수에서는 내부적으로 recursion 을 사용하는데 recursion 을 사용하겠다는 것은 다시 말해서 자동으로 stack 을 사용하겠다는 것입니다 ( 함수가 호출되면 자동으로 매개변수 및 지역변수가 stack 에 push 되고 return 시에는 pop 되므로 ). 따라서 stack 자료구조를 사용할 수 있을 경우에는 recursion 없이 다음과 같이 해도 동일한 결과가 됩니다.
switch (token[cdx]) {
case "{" :
case "[" :
push(stack, path ) # 기존 path, sblock 변수값을
push(stack, sblock ) # stack 에 push 해서 저장하고
path = path "/" ckey # 변수값을 새로 설정
sblock = cdx++
break
case "}" :
case "]" :
sblock = pop(stack) # stack 에 저장해 놓은 path, sblock
path = pop(stack) # 변수값을 pop 해서 복구
break
case ":" :
3.
위의 sample.json 데이터에서 각 멤버 블록을 DESC age 순으로 출력하려면 어떻게 할까요?
$ ./json.sh -s /members/name sample.json |
xargs -i ./json.sh -s /members/name="{}" sample.json |
awk '"{" == $0 { res = "{"; next }
{ if ( $1 ~ /"age"/ ) idx = $2 i++; res = res "\n" $0 }
"}" == $0 { a[idx] = res }
END { PROCINFO["sorted_in"] = "@ind_num_desc"; for (i in a) print a[i] }
'
{
"name": "Eternal Flame",
"age": 1000000,
"secretIdentity": "Unknown",
"powers": [
"Immortality",
"Heat Immunity",
"Inferno",
"Teleportation",
"Interdimensional travel"
]
}
{
"name": "Madame Uppercut",
"age": 39,
"secretIdentity": "Jane Wilson",
"powers": [
"Million tonne punch",
"Damage resistance",
"Superhuman reflexes"
]
}
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes",
"powers": [
"Radiation resistance",
"Turning tiny",
"Radiation blast"
]
}