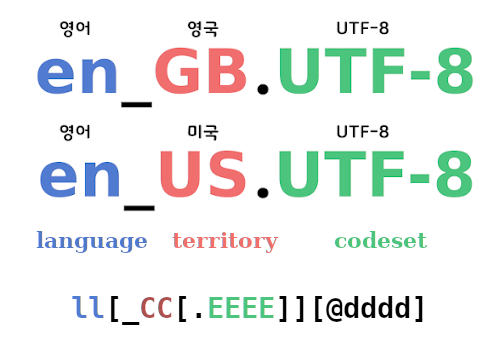
Locale
로케일(Locale)에 관하여...
http://coffeenix.net/doc/misc/locale.html로케일이 필요한 이유
https://miaow-miaow.tistory.com/43유니코드란 무엇일까?
https://norux.me/31
예전에는 각 나라별로 문자 세트와 인코딩 방법을 사용했습니다. 예를 들어 일본의 경우는 JIS X 0208 문자 세트에 EUC_JP, Shift_JIS 인코딩을 사용하고 한국은 KS X 1001 문자 세트에 EUC_KR, CP949 인코딩을 사용하는 식이었습니다. 이렇게 각 나라별로 문자 세트와 인코딩 방법을 사용하다 보니 한국에서 외국 사이트를 볼 때나 외국에서 한국 사이트를 볼 때 글자가 깨져서 볼 수 없는 경우가 많았습니다. 따라서 전 세계의 문자를 모두 모아 하나의 문자 세트로 통일하고( unicode ) 이를 기반으로 한 인코딩 방식을 만든 것이 UTF ( Unicode Transformation Format ) 입니다. UTF 를 이용하면 하나의 페이지에서 전 세계의 글자를 모두 볼 수가 있습니다.
# Go 언어 입니다.
$ ( cd `mktemp -d -p /dev/shm 2>&1` && trap "rm -rf '$PWD'" 0 && go mod init hello && cat <<\@ > main.go && go mod tidy && go build && mv hello "$OLDPWD" )
package main
import "rsc.io/quote"
func main() {
println(quote.Hello())
}
@
$ LANG=en_US.UTF-8 ./hello $ LANG=ja_JP.UTF-8 ./hello
Hello, world. こんにちは世界。
$ LANG=ko_KR.UTF-8 ./hello $ LANG=zh_CN.UTF-8 ./hello
안녕, 세상. 你好,世界。
로케일 설정하기
Ubuntu 의 경우 /etc/default/locale 파일에서 로케일을 설정할 수 있습니다
( plasma-desktop 의 경우는 ~/.config/plasma-localerc ).
LC_* 로 시작하는 변수들이 locale category 를 설정하는 변수들인데
LANG 은 전체 디폴트 값을 설정할 때 사용하고
LC_ALL 는 기존 설정값들을 모두 override 할 때 사용합니다.
따라서 우선순위는 LC_ALL 가 제일 높고 그다음이 각 LC_* 변수들, 마지막이 LANG 값입니다.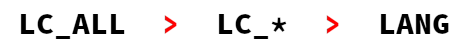
# 디폴트 값을 C.UTF-8 로 설정 # 디폴트 값을 ko_KR.UTF-8 로 설정
$ cat /etc/default/locale $ cat /etc/default/locale
LANG=C.UTF-8 LANG=ko_KR.UTF-8
$ locale $ locale
LANG=C.UTF-8 LANG=ko_KR.UTF-8
LANGUAGE= LANGUAGE=
LC_CTYPE="C.UTF-8" LC_CTYPE="ko_KR.UTF-8"
LC_NUMERIC="C.UTF-8" LC_NUMERIC="ko_KR.UTF-8"
LC_TIME="C.UTF-8" LC_TIME="ko_KR.UTF-8"
LC_COLLATE="C.UTF-8" LC_COLLATE="ko_KR.UTF-8"
LC_MONETARY="C.UTF-8" LC_MONETARY="ko_KR.UTF-8"
LC_MESSAGES="C.UTF-8" LC_MESSAGES="ko_KR.UTF-8"
. . . . . .
LC_ALL= LC_ALL=
---------------------------------------------------------------------
# 디폴트 값은 en_US.UTF-8 로 설정하고
# LC_COLLATE 만 ko_KR.UTF-8 로 설정 # LC_ALL 을 이용해 기존 값들을 모두 override
$ cat /etc/default/locale $ cat /etc/default/locale
LANG=en_US.UTF-8 LANG=en_US.UTF-8
LC_COLLATE=ko_KR.UTF-8 LC_COLLATE=ko_KR.UTF-8
$ locale $ LC_ALL=C locale
LANG=en_US.UTF-8 LANG=en_US.UTF-8
LANGUAGE= LANGUAGE=
LC_CTYPE="en_US.UTF-8" LC_CTYPE="C"
LC_NUMERIC="en_US.UTF-8" LC_NUMERIC="C"
LC_TIME="en_US.UTF-8" LC_TIME="C"
LC_COLLATE="ko_KR.UTF-8" LC_COLLATE="C"
LC_MONETARY="en_US.UTF-8" LC_MONETARY="C"
LC_MESSAGES="en_US.UTF-8" LC_MESSAGES="C"
. . . . . .
LC_ALL= LC_ALL=C
C , POSIX 로케일
locale -a 명령을 실행했을 때 기본적으로 볼 수 있는 C 로케일은
1 byte ASCII 문자만 다루는 일종의 Computer ( C programming ) 로케일 입니다.
POSIX 는 C 의 alias 로 같은 것입니다.
C.UTF-8 는 UTF-8 인코딩도 처리할 수 있게 확장한 것으로,
로케일을 C 로 설정하면 한글 입력이 안되지만 C.UTF-8 로 설정하면
한글도 입력할 수 있습니다 ( 한글, 일본어, 중국어... 모든 언어가 UTF-8 로 처리되므로 ).
binary 데이터를 다룰때 는
C로케일을 사용해야 합니다.
로케일 적용 예
로케일 설정에 따라서 터미널이나 에디터에서 한글 입력이 안되거나 sort, uniq, grep 같은 명령들이 정상적으로 실행되지 않을 수 있습니다.
ls 명령
# "en_US.UTF-8" 은 한글이 제일 위에 오고 다음 특수문자, 알파벳이 옵니다.
# 알파벳은 대, 소문자 구분 없이 출력되는 것을 볼 수 있습니다.
$ LC_ALL=en_US.UTF-8 \ls -l
total 0
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 돼지
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 강아지
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 코끼리
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 @@@
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 aaa
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 AAA
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 bbb
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 BBB
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 ccc
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 CCC
# "ko_KR.UTF-8", "C.UTF-8", "C" 는 모두 특수문자가 제일 위에 오고 알파벳, 한글 순으로 출력됩니다.
# 알파벳이 출력될 때는 대문자가 먼저 오고 다음에 소문자가 옵니다.
# 영문 "May" 가 한글 "5월" 로 출력되는 것을 볼 수 있습니다.
$ LC_ALL=ko_KR.UTF-8 \ls -l
total 0
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:21 @@@
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:21 AAA
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:21 BBB
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:21 CCC
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:21 aaa
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:21 bbb
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:21 ccc
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:20 강아지
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:20 돼지
-rw-rw-r-- 1 mug896 mug896 0 5월 10 11:20 코끼리
# 출력 순서는 위와 동일하며 May 가 영문으로 출력됩니다.
$ LC_ALL=C.UTF-8 \ls -l
total 0
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 @@@
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 AAA
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 BBB
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 CCC
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 aaa
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 bbb
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 ccc
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 강아지
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 돼지
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 코끼리
# LC_ALL=C 는 UTF-8 인코딩이 적용되지 않아 한글이 깨져 보입니다.
$ LC_ALL=C \ls -l
total 0
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 @@@
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 AAA
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 BBB
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 CCC
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 aaa
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 bbb
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:21 ccc
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 ''$'\352\260\225\354\225\204\354\247\200'
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 ''$'\353\217\274\354\247\200'
-rw-rw-r-- 1 mug896 mug896 0 May 10 11:20 ''$'\354\275\224\353\201\274\353\246\254'
위에서 출력 순서를 보면 ko_KR.UTF-8, C.UTF-8, C 는 모두 특수문자가 제일 위에 오고
알파벳, 한글 순으로 출력이 되는데 이것은 단순히 비트 값의 크기에 따라서 출력하기 때문입니다.
$ echo -e "@@@\nAAA\nBBB\naaa\nbbb\n강\n돼"
@@@
AAA
BBB
aaa
bbb
강
돼
$ echo -e "@@@\nAAA\nBBB\naaa\nbbb\n강\n돼" | perl -lpe '$_=unpack "B*"'
010000000100000001000000
010000010100000101000001
010000100100001001000010
011000010110000101100001
011000100110001001100010
111010101011000010010101
111010111000111110111100
date 명령
$ LC_TIME=en_US.UTF-8 date
Sun 10 May 2020 11:49:04 AM KST
$ LC_TIME=ko_KR.UTF-8 date
2020. 05. 10. (일) 11:49:12 KST
$ LC_TIME=ko_KR date # ko_KR.UTF-8 에서 .UTF-8 을 빼면 한글이 깨진다.
2020. 05. 10. (��) 11:52:54 KST
$ LC_TIME=C.UTF-8 date # C.UTF-8 와 C 는 동일한 결과
Sun May 10 11:49:15 KST 2020
$ LC_TIME=C date
Sun May 10 11:49:17 KST 2020
sort 명령
$ echo -e 'B\n나\nA\nb\n가\na\n다'
B
나
A
b
가
a
다
# "en_US.UTF-8" 은 한글은 정렬이 안되고 알파벳은 대,소문자 구분 없이 정렬된다.
$ echo -e 'B\n나\nA\nb\n가\na\n다' | LC_COLLATE=en_US.UTF-8 sort
나
가
다
a
A
b
B
# "ko_KR.UTF-8", "C.UTF-8", "C" 은 모두 비트값에 따라 정렬하므로 결과가 같다.
$ echo -e 'B\n나\nA\nb\n가\na\n다' | LC_COLLATE=C.UTF-8 sort
A
B
a
b
가
나
다
$ echo -e 'B\n나\nA\nb\n가\na\n다' | LC_COLLATE=C.UTF-8 sort | perl -lpe '$_=unpack "B*"'
01000001
01000010
01100001
01100010
111010101011000010000000
111010111000001010011000
111010111000101110100100
uniq 명령
$ echo -e '가\n나\n나\n다'
가
나
나
다
# "en_US.UTF-8" 은 한글을 정상적으로 처리하지 못한다.
$ echo -e '가\n나\n나\n다' | LC_COLLATE=en_US.UTF-8 uniq
가
# "ko_KR.UTF-8", "C.UTF-8", "C" 은 모두 비트값에 따라 정렬하므로 결과가 같다.
$ echo -e '가\n나\n나\n다' | LC_COLLATE=C.UTF-8 uniq
가
나
다
1,000 자리마다 콤마 넣기
printf 명령에서 ' flag 을 이용한 콤마 넣기는 C 로케일 에서는 지원이 되지 않습니다.
$ LC_NUMERIC=C printf "%'d\n" 123456789
123456789
$ LC_NUMERIC=C.UTF-8 printf "%'d\n" 123456789
123456789
$ LC_NUMERIC=en_US.UTF-8 printf "%'d\n" 123456789
123,456,789
$ LC_NUMERIC=ko_KR.UTF-8 printf "%'d\n" 123456789
123,456,789
$ LC_ALL=en_US.UTF-8 printf "%'d\n" 123456789
123,456,789
$ gcc -xc - <<\@ && ./a.out
#include <stdio.h>
#include <sys/sysinfo.h>
#include <locale.h>
int main() {
struct sysinfo info;
sysinfo(&info);
setlocale(LC_NUMERIC, "en_US.UTF-8");
printf("totalram : %'lu\n", info.totalram);
printf("freeram : %'lu\n", info.freeram);
printf("sharedram : %'lu\n", info.sharedram);
printf("bufferram : %'lu\n", info.bufferram);
printf("totalswap : %'lu\n", info.totalswap);
printf("freeswap : %'lu\n", info.freeswap);
return 0;
}
@
totalram : 16,686,063,616
freeram : 902,701,056
sharedram : 1,018,851,328
bufferram : 1,233,055,744
totalswap : 2,147,479,552
freeswap : 1,207,369,728
C 로케일을 사용해야 될 때
C.UTF-8 은 UTF-8 인코딩을 처리하기 때문에
binary 데이터를 다룰때 는 C 로케일을 사용해야 합니다.
$ echo -e "Testing this: \xC0 byte" | LC_CTYPE=en_US.UTF-8 grep -P '\xC0'
$
$ echo -e "Testing this: \xC0 byte" | LC_CTYPE=ko_KR.UTF-8 grep -P '\xC0'
$
$ echo -e "Testing this: \xC0 byte" | LC_CTYPE=C.UTF-8 grep -P '\xC0'
$
$ echo -e "Testing this: \xC0 byte" | LC_CTYPE=C grep -P '\xC0'
Testing this: � byte
$ echo -e "Testing this: \xC0 byte" | LC_ALL=C grep -P '\xC0'
Testing this: � byte
regex 에서 사용되는 [[:alpha:]] 클래스는 UTF-8 인코딩을 사용할 경우 한글도 모두 매칭이 됩니다.
만약에 [[:alpha:]] 가 [a-zA-Z] 와 같은 의미를 갖게 하려면 LC_CTYPE=C 를 사용해야 합니다.
$ echo abc | grep '[[:alpha:]]'
abc
$ echo 가나다 | grep '[[:alpha:]]'
가나다
$ echo 가나다 | LC_CTYPE=C.UTF-8 grep '[[:alpha:]]'
가나다
$ echo abc | LC_CTYPE=C grep '[[:alpha:]]'
abc
$ echo 가나다 | LC_CTYPE=C grep '[[:alpha:]]'
$
$ echo 가나다 | LC_ALL=C grep '[[:alpha:]]'
$
로케일 설치
시스템에 로케일이 설치되어 있지 않으면 C/C++ 프로그램 작성시 오류가 발생할 수 있습니다. 이때는 다음과 같이 해당 로케일을 설치해 주면 됩니다.
#include <ctime>
#include <iomanip>
#include <iostream>
int main()
{ // en_US, ko_KR, ja_JP 로케일을 변경해가며 날짜를 출력.
const std::time_t now = std::time(nullptr);
for (const char *localeName : {"C", "en_US.utf8", "ko_KR.utf8", "ja_JP.utf8" })
{
std::cout << "locale " << localeName << ":\n" << std::left;
std::locale::global(std::locale(localeName));
char buf[64];
if (strftime(buf, sizeof buf, "%c\n", std::localtime(&now)))
std::cout << std::setw(40) << " strftime %c" << buf;
if (strftime(buf, sizeof buf, "%a %b %e %H:%M:%S %Y\n", std::localtime(&now)))
std::cout << std::setw(40) << " strftime %a %b %e %H:%M:%S %Y" << buf;
std::cout << '\n';
}
}
-------------------------------------------------------------------------
$ g++ test.cpp
$ ./a.out
. . .
locale ko_KR.utf8:
strftime %c 2022년 01월 08일 (토) 오전 09시 00분 21초
strftime %a %b %e %H:%M:%S %Y 토 1월 8 09:00:21 2022
locale ja_JP.utf8: // 현재 시스템에 ja_JP 로케일이 없어 오류발생.
terminate called after throwing an instance of 'std::runtime_error'
what(): locale::facet::_S_create_c_locale name not valid
Aborted (core dumped)
$ sudo apt install language-pack-ja // ja_JP 언어팩 설치
$ locale -a | grep ja_JP
ja_JP.utf8
$ ./a.out // 이제 정상적으로 실행이 된다.
. . .
locale ja_JP.utf8:
strftime %c 2022年01月08日 09時03分19秒
strftime %a %b %e %H:%M:%S %Y 土 1月 8 09:03:19 2022
메시지 localization
쉘 스크립트 실행시 출력되는 메시지에 localization 을 제공할 수 있습니다.
가령 LANGUAGE 가 ko_KR 이면 메시지가 한글로 출력이 되고 ja_JP 면 일본어로 출력이 됩니다.
$ wc -x
wc: invalid option -- 'x'
Try 'wc --help' for more information.
$ LANGUAGE=ko_KR wc -x
wc: 부적절한 옵션 -- 'x' # 여기서는 "invalid option" 스트링이
Try 'wc --help' for more information. # localization 되어 있음.
$ LANGUAGE=ja_JP wc -x
wc: 無効なオプション -- 'x'
Try 'wc --help' for more information.
이번에는 직접 foobar.sh 명령에 대한 localization 을 설정해 보겠습니다.
먼저 localization 에 사용할 스트링을 다음과 같이 $"..." quotes 이용해 작성합니다.
$ cat foobar.sh
#!/bin/bash
echo $"info"': message1...' # $"info"
echo $"warn"': message2...' # $"warn"
echo $"error"': message3...' # $"error"
opt="--xyz"
echo $"invalid option -- '$opt'" # $"invalid option -- '$opt'"
printf $"%s: invalid option -- '%s'\n" "foo" "$opt" # $"%s: invalid option -- '%s'\n"
그다음 bash 의 --dump-po-strings 옵션을 이용해 foobar.sh 를 실행하면
다음과 같은 template 파일을 얻을 수 있습니다.
( --dump-po-strings 옵션은 기본적으로 -n ( noexec ) 옵션을 포함하므로 실제 명령이 실행되지는 않습니다. )
$ bash --dump-po-strings ./foobar.sh > foobar.pot
$ cat foobar.pot
#: ./foobar.sh:5
msgid "info" # msgid 는 $"..." quotes 을 이용해 작성한 스트링이 되고
msgstr "" # msgstr 은 사용자가 직접 각 언어에 맞게 입력합니다.
#: ./foobar.sh:6
msgid "warn"
msgstr ""
#: ./foobar.sh:7
msgid "error"
msgstr ""
#: ./foobar.sh:9
msgid "invalid option -- '$opt'"
msgstr ""
#: ./foobar.sh:10
msgid "%s: invalid option -- '%s'\\n"
msgstr ""
msgstr 에는 지원하고자 하는 언어에 맞게 다음과 같이 값을 채워주면 됩니다.
$ cp foobar.pot ko_foobar.po $ cp foobar.pot ja_foobar.po
$ cat ko_foobar.po $ cat ja_foobar.po
#: ./foobar.sh:5 #: ./foobar.sh:5
msgid "info" msgid "info"
msgstr "정보" msgstr "情報"
#: ./foobar.sh:6 #: ./foobar.sh:6
msgid "warn" msgid "warn"
msgstr "경고" msgstr "警告"
#: ./foobar.sh:7 #: ./foobar.sh:7
msgid "error" msgid "error"
msgstr "오류" msgstr "誤謬"
#: ./foobar.sh:9 #: ./foobar.sh:9
msgid "invalid option -- '$opt'" msgid "invalid option -- '$opt'"
msgstr "잘못된 옵션 -- '$opt'" msgstr "間違ったオプション -- '$opt'"
#: ./foobar.sh:10 #: ./foobar.sh:10
msgid "%s: invalid option -- '%s'\\n" msgid "%s: invalid option -- '%s'\\n"
msgstr "%s: 잘못된 옵션 -- '%s'\\n" msgstr "%s: 間違ったオプション -- '%s'\\n"
그다음 msgfmt 명령을 이용해 .mo 파일로 변경한 후 각 언어의 LC_MESSAGES 디렉토리에
설치해 줍니다.
gettext 명령을 이용해 테스트를 해보면 msgid 에 해당하는 스트링이 LANGUAGE 설정에 따라
변경되어 출력되는 것을 볼 수 있습니다.
마지막으로 foobar.sh 명령의 상단에 TEXTDOMAIN=foobar 를 추가해 주면 됩니다.
$ sudo msgfmt ko_foobar.po -o /usr/share/locale/ko/LC_MESSAGES/foobar.mo
$ sudo msgfmt ja_foobar.po -o /usr/share/locale/ja/LC_MESSAGES/foobar.mo
$ LANGUAGE=ko_KR gettext --domain=foobar -s "info"
정보
$ LANGUAGE=ja_JP gettext --domain=foobar -s "info"
情報
$ cat foobar.sh
#!/bin/bash
TEXTDOMAIN=foobar # 메시지 localization 을 위해 추가
. . . # (여기서 foobar 는 foobar.mo 파일명)
$ LANGUAGE=ko_KR ./foobar.sh $ LANGUAGE=ja_JP ./foobar.sh
정보: message1... 情報: message1...
경고: message2... 警告: message2...
오류: message3... 誤謬: message3...
잘못된 옵션 -- '--xyz' 間違ったオプション -- '--xyz'
foo: 잘못된 옵션 -- '--xyz' foo: 間違ったオプション -- '--xyz'
좀더 자세한 내용은: http://mywiki.wooledge.org/BashFAQ/098
참고
출력 메시지나 메뉴 등 전체적으로 한글 환경을 사용하고 싶으면
LANG=ko_KR.UTF-8로 설정해 사용하고출력 메시지나 메뉴 등 전체적으로 영문 환경을 사용하고 싶지만 한글 입, 출력 및 명령 실행 시에 한글 처리도 정상적으로 되게 하려면
LANG=C.UTF-8로 설정해 사용하고binary 데이터를 다룰 때는
LC_ALL=C를 사용하면 됩니다.
키보드 레이아웃
리눅스에서는 키보드 레이아웃을 kr 로 설정하면 오른쪽 alt, ctrl 키가 hangul, hanja
키로 맵핑이 되어서 사용할 수 없게 됩니다.
키보드의 오른쪽에도 alt, ctrl 키가 있는 것은 한 손으로 입력이 어려울 경우 활용하기 위해서인데요.
가령 alt-shift-! 키 조합을 입력하려면 한 손으로는 입력하기가 어렵습니다.
이럴 경우 오른손으로는 alt 키를 누르고 왼손으로는 shift-! 키를 누르면 쉽게 입력이 됩니다.
윈도우즈에서는 주로 마우스를 사용하기 때문에 alt, ctrl 키가 왼쪽에만 있어도 되지만
리눅스에서는 오른쪽 alt, ctrl 키도 많이 사용되므로
키보드 레이아웃을 us 로 설정해 사용하는 것이 좋은 것 같습니다.
Quiz
터미널에서 "한글" 을 UTF-8 인코딩 방식으로 출력해보고
아래 표를 참고하여 unicode 로도 출력해 보세요
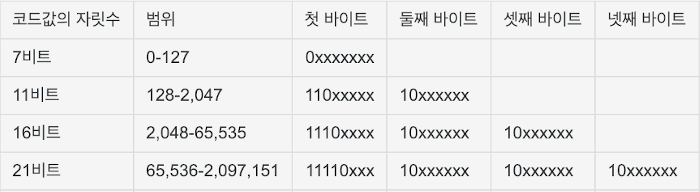
UTF-8 은 가변 인코딩 방식으로 1 ~ 4 bytes 가 사용됩니다. ASCII 문자는 기존과 같이 1 byte 만 사용되므로 아주 효율적인 방식입니다. unicode 는 글자와 1:1 맵핑되는 단순 코드표 값입니다. 이 코드표 값을 가지고 여러 가지 방법으로 인코딩해 사용하는데 그중 하나가 UTF-8 입니다. UTF-8 은 값을 구분하기 위해 2 bytes 가 사용될 때는 첫 번째 바이트가
110로 시작하고 3 bytes 가 사용될 때는 첫 번째 바이트가1110로 ... 시작합니다. 나머지 바이트는10로 시작합니다. 표에 보이는 xxxxx 로된 자리에 unicode 값이 들어갑니다.
$ echo -n 한글 | od -An -tx1
ed 95 9c ea b8 80
$ echo -e '\xed\x95\x9c\xea\xb8\x80' # UTF-8 : 글자당 3 bytes 로 인코딩
한글
------------------------------------
$ echo -n 한글 | perl -lpe '$_=join(" ", unpack "(B8)*")'
11101101 10010101 10011100 11101010 10111000 10000000
^^^^ ^^^^^^ ^^^^^^ ^^^^ ^^^^^^ ^^^^^^
\_____ 한 ______/ \_____ 글 ______/
$ printf %x $(( 2#1101010101011100 ))
d55c
$ printf %x $(( 2#1010111000000000 ))
ae00
$ echo -e '\Ud55c\Uae00' # unicode
한글
2.
shell 에서 한글 입력이 되지 않아 locale 을 조회해 보니 POSIX 로 출력됩니다.
한글 입력이 되게 하려면 어떻게 해야 할까요?
$ export LANG=C.UTF-8 # LANG=C.UTF-8 값으로 새로 bash 프로세스를 실행합니다.
$ exec bash --login # --login 옵션을 사용해야 .profile 을 읽어들이겠죠.
# 또는
$ LANG=C.UTF-8 exec bash --login