Readline
CLI (command line interface) 를 사용하는 프로그램에서 line editing, 명령 history,
brace 확장, 명령 자동완성과 같은 기능을 제공하는 라이브러리로 shell 프롬프트 상에서
명령문을 작성할때 사용하는 키조합이나 history 기능은 이 라이브러리를 이용하는 것입니다.
line editing 에는 emacs 와 vi 두 종류의 키조합을 제공하는데 기본 설정은 emacs 이며
set -o emacs or set -o vi 옵션을 통해 변경할 수 있습니다.
man 페이지는
man 3 readline명령으로 볼 수 있습니다.
Readline init file
readline 은 ~/.inputrc 설정 파일을 통해 옵션을 설정하고 키조합을 커스터마이징 할 수 있습니다.
다음은 completion-ignore-case 옵션을 설정하여 tab 및 alt-/ 키를 이용한 자동완성 시에 대, 소문자 구분없이 하고
alt-space 에는 "git " 을 ctrl-space 에는 "docker " 스트링이 프롬프트 상에 입력되게 하며 펑션키 F9, F10 에는 자주 사용하는 명령을 바인딩하는 예입니다.
키 조합에 사용되는 키값은 Ctrl-v 나 read 명령을 이용하여 구할 수 있습니다.
구한 키값에서 ^[ 문자를 \e 로 수정하여 사용합니다.
# Ctrl-v 입력 후 F9 키를 누른 상태
$ ^[[20~
$ read # enter 후에 원하는 키를 입력
^[[20~ # 키값은 터미널별로 다른값이 나올 수 있습니다.
inputrc 파일을 수정한 후에 Ctrl-x Ctrl-r 를 입력하거나 새로 터미널 창을 열면 설정된 기능을 사용할 수 있습니다. 한가지 유의할 점은 window manager 나 터미널창 자체에서 이미 키조합이 설정돼있으면 적용이 되지 않으므로 필요없는 키조합은 먼저 삭제하시기 바랍니다.
~/.inputrc 활용 예제
# 대,소문자 구분없이 word completion
set completion-ignore-case on
# 모드 설정을 하지 않을경우 default 는 emacs 입니다.
# emacs 모드로 설정
# set editing-mode emacs
# vi 모드로 설정
# set editing-mode vi
# emacs 모드일경우 적용
# $if mode=emacs
# ctrl + enter 누르면 현재 명령행 상에 있는 전체 내용 삭제
"\e[9;8~": kill-whole-line
# alt-space 치면 프롬프트에 git 입력
"\e ": "git "
# ctrl-space 치면 프롬프트에 docker 입력
"\C-@": "docker "
# Shift-F1 키에 fzf 명령을 바인딩 합니다.
# fuzzy finder 는 Junegunn Choi 님이 Go 언어로 만든 명령이죠. 리눅스 소스 같은
# 많은 파일이 존재하는 디렉토리에서 파일 이름을 빠르고 쉽게 찾을 수 있습니다.
"\eO2P": " \C-u$(fzf -m)\e\C-e\C-a\C-y\b\C-e"
# 이 함수는 원래 \C-x\C-e 키에 바인딩 되어있는데 한 번에 실행하기 위해
# F2 키에 바인딩 합니다. 현재 명령행 상에서 작성 중인 내용과 함께 vi 에디터가 열립니다.
"\eOQ": edit-and-execute-command
# \C-k\C-u 는 각각 kill-line, unix-line-discard 함수로 바인딩되어 있으므로
# 현재 프롬프트에 입력돼있는 스트링을 모두 삭제합니다. \C-m 은 enter 를 의미합니다.
# F11 키에 git pull 명령 바인딩
"\e[23~": "\C-k\C-ugit pull\C-m"
"\e[23;2~": "\C-k\C-ugit diff @{1}\C-m"
# F12 키에 git push 명령 바인딩
"\e[24~": "\C-k\C-ugit push\C-m"
# 기존 키바인딩을 undefined 하고 싶으면
# "키값": nop
# $endif
현재 바인딩 되어있는 사용자 정의 키조합은
bind -s명령으로 조회해 볼 수 있습니다.bind -v로는 현재 설정되어 있는 readline 옵션을 조회해 볼 수 있습니다.
유용한 키보드 shortcut
이전 명령에서 사용된 마지막 인수를 입력하고 싶을 때는
Alt-.을 이용하면 됩니다. 연속해서 누르면 이전 명령으로 이동합니다.Ctrl-r은 명령 history 를 검색하여 입력한 패턴에 해당하는 명령을 불러와 실행할 수 있게 해줍니다. 연속해서 누르면 매칭되는 다음 항목으로 넘어갑니다. ( 다시 앞쪽으로 검색은Ctrl-s)프롬프트 상에서 명령문을 작성 중에 에디터를 불러오고 싶을 때
Ctrl-x Ctrl-e를 입력하면 현재 작성 중인 내용과 함께 vi editor 가 열립니다.:wq명령으로 vi 를 종료하면 수정된 명령이 실행되고:cq명령으로 종료하면 실행되지 않습니다.
실행되는 에디터를 변경할 수 있는데
$VISUAL,$EDITOR변수값 설정 순서에 따릅니다.
tab 키로 파일이름 자동완성이 되지 않을 경우
Alt-/로 자동완성을 할 수 있습니다.그 외 여러 키조합은 http://readline.kablamo.org/emacs.html 에서 볼 수 있습니다. 이전에 실행된 키조합을 undo (
Ctrl-/) 할수도 있고 cut & paste 도 할 수 있습니다.여러 단계의 키조합이 설정되어 사용될 경우 키조합 입력 중간에 취소하는 방법은
Ctrl-g입니다.
현재 바인딩 되어있는 readline 함수 키조합은
bind -p명령으로 조회해 볼 수 있고bind -l명령으로 사용 가능한 readline 함수 목록을 볼 수 있습니다.
명령이 readline 기능을 제공하지 않을 경우
명령이 readline 기능을 제공하지 않을 경우 editing 키 조합이나 history 같은 기능을
사용할 수 없어 불편한데요. 이때는 rlwrap 명령을 사용해 볼 수 있습니다.
perl 언어의 경우 요즘 나오는 언어들과 달리 명령을 실행해 볼 수 있는
REPL (Read Evaluate Print Loop) 기능이 없는데요.
하지만 디버깅 모드에서 비슷하게 실행해 볼 수 있습니다.
다음과 같이 rlwarp 명령을 이용하면 디버깅 모드에서도 readline 기능을 사용할 수 있습니다.
$ alias perldebug='rlwrap perl -de1'
Quiz
앞서 이전 명령에서 사용된 마지막 인수는 Alt-. 키조합을 이용하여 입력할 수 있다고 하였는데요
그럼 마지막 인수가 아닌 경우는 어떻게 입력할까요?
똑같이
Alt-.키조합을 이용하지만 그전에 인수의 위치를Alt-숫자로 먼저 지정을 합니다.
예를 들면 이전 명령에서 사용된 2 번째 인수를 입력하고 싶다면Alt-2 Alt-.을 입력하면 됩니다.
Alt-숫자대신에Alt--(minus) 를 누르면 어떻게 될까요?
cut & paste, copy & paste
이 기능은 kill ring 과 Ctrl-y (yank) 함수를 이용합니다. 이름이 좀 생소한데 예전에는 cut & paste 라고 하지 않고 kill, yank 라고 했다고 합니다. Ctrl-u, Ctrl-k, Ctrl-w, Alt-backspace 같은 키조합들은 작성한 명령문의 일부분을 삭제하는데 이때 삭제된 내용이 kill ring 에 들어갑니다. 이후에 Ctrl-y 를 이용하여 paste 할 수 있습니다. 여기서 kill ring 이라고 하는 이유는 paste 할때 Alt-y 로 이전 값을 불러올 수가 있기 때문입니다.
다음은 Ctrl-w (공백을 기준으로 이전 스트링 삭제) 와 Alt-backspace (단어를 기준으로 이전 스트링 삭제) 를 이용해 cut & paste 를 하는 예입니다. cut 한 다음에 바로 paste 하면 copy & paste 를 할 수 있습니다.
Ctrl-w 와 Alt-backspace 는 공백과 단어를 기준으로 이전 스트링을 삭제하기 때문에 종종 kill 하고자 하는 경계가 맞지 않는 경우가 있습니다. 이때는 mark 와 kill 을 이용하여 직접 region 을 지정할 수 있습니다. 이 기능을 이용하기 위해서는 먼저 ~/.inputrc 에 다음과 같은 설정을 합니다.
# ~/.inputrc 에 추가할 내용
# Alt-m : 현재 커서위치에 mark 설정
"\em": set-mark
# Alt-k : mark 한 위치부터 현재 커서까지 내용을 kill ring 에 copy.
"\ek": copy-region-as-kill
# Alt-Shift-k : mark 한 위치부터 현재 커서까지 내용을 copy 함과 동시에 삭제.
"\eK": kill-region
bind toggling
다음은 bind 명령을 이용한 toggling 입니다.
Ctrl-space 에 docker 가 바인딩 되어 있는데 F1 키를 이용해서 lxc 로 토글하는 기능입니다.
# bind -x 명령은 .inputrc 에서 설정할 수 없으므로 다음 내용을 .bashrc 에 추가합니다.
# F1 키를 toggle 키로 설정합니다.
bind -x '"\eOP": "source ~/bin/bind_toggle.sh"'
---------------------------------------------------------
# ~/bin/bind_toggle.sh 파일의 내용
# source 명령으로 읽어 들이므로 shebang 라인과 실행 권한은 필요 없습니다.
case $(bind -S | grep -P -m1 -o "(?<=C-@ outputs )\S+") in
git)
bind '"\C-@": "docker "'
echo docker
;;
docker)
bind '"\C-@": "lxc "'
echo lxc
;;
lxc)
bind '"\C-@": "git "'
echo git
;;
esac
토글 단어를 여러개 사용하면 현재 설정을 알기 어려우므로 프롬프트에 표시해 주면 좋습니다.
~/.bashrc 파일의 PS1 프롬프트 설정하는 곳을 찾아서 적당한 위치를 정하여
+= 연산자를 이용해 다음과 같이 추가해 줍니다.
설정된 값은 토글키를 누른 후 다음번 프롬프트가 표시될때 변경 됩니다.
# ~/.bashrc 파일에서 PS1 프롬프트 설정
bind '"\C-@": "git "' # 초기값
PS1+='$(
case $(bind -S | grep -P -m1 -o "(?<=C-@ outputs )\S+") in
git) echo G ;;
docker) echo D ;;
lxc) echo L ;;
esac
)'
Command line history expansion
현재 작성 중인 명령 행상에서 앞서 타입한 인수를 다시 입력하고 싶을 때가 있습니다.
readline 함수인 history-expand-line 과 !#:$ !#:0 !#:1 ... command history 기능을 이용해
Alt-숫자 Alt-, 키조합에 바인딩 해보겠습니다.
한가지 사용시 주의할 점은 이 키조합은 앞서 Alt-숫자 Alt-. 에서 사용되는 Alt-숫자 와
중복되므로 좀 빠르게 눌러야 됩니다.
# ~/.inputrc 에 추가할 내용
# "Alt-," 에는 !#:$ 을 바인딩 하고
# "Alt-1 Alt-," 에는 !#:1 을 "Alt-2 Alt-," 에는 !#:2 ... 을 각각 바인딩 합니다.
# "\e^" 는 history-expand-line 함수입니다. 앞서 입력한 !#:1 부분이 확장됩니다.
"\e1\e,": "!#:1\e^"
"\e2\e,": "!#:2\e^"
"\e3\e,": "!#:3\e^"
"\e4\e,": "!#:4\e^"
"\e5\e,": "!#:5\e^"
"\e6\e,": "!#:6\e^"
"\e7\e,": "!#:7\e^"
"\e8\e,": "!#:8\e^"
"\e9\e,": "!#:9\e^"
"\e0\e,": "!#:0\e^"
"\e,": "!#:$\e^"
이전 명령의 출력 결과를 사용
명령문을 작성할 때 이전 명령문이 아니라 명령의 출력 결과를 사용하고 싶을 때가 있습니다.
.inputrc 에 다음과 같은 설정을 통해 이전 명령의 출력을 입력할 수 있습니다.
WARNING!!!이것은 history 확장을 이용해서 이전 명령을 다시 실행시키는 것입니다. 따라서 재실행하면 안되거나 시간이 오래 걸리는 명령일 경우 사용하면 안되겠죠.
# "\e[20~" : F9 키로 설정합니다. "\e[20;2~" 는 SHIFT-F9 입니다.
# \C-u : 현재까지 타입한 명령을 삭제함과 동시에 copy 합니다.
# $(...)\e\C-e : \e\C-e 는 shell-expand-line 함수로 앞서 입력한 $(...) 부분이 확장됩니다.
# \C-a : 커서를 라인 처음으로 옮깁니다.
# \C-y : yank 함수로 paste 에 해당합니다. 앞서 \C-u 로 copy 했던 부분을 붙여 넣습니다.
# \b : 처음에 한칸 띄었으므로 없애기 위해 backspace
# \C-e : 커서를 라인 끝으로 옮깁니다.
# F9 키 : 마지막 단어
"\e[20~": " \C-u$( { !! ;} |& awk '$NF {W = $NF} END{print W}' )\e\C-e\C-a\C-y\b\C-e"
# Shift-F9 : 마지막 라인
"\e[20;2~": " \C-u$( { !! ;} |& sed -n '/\\S/h; ${g;p}' )\e\C-e\C-a\C-y\b\C-e"
# Ctrl-F9 : 전체 내용
"\e[20;5~": " \C-u$( { !! ;} 2>&1 )\e\C-e\C-a\C-y\b\C-e"
특정 사이즈의 인수를 간단히 입력
만약에 1000, 1024, 4096 bytes 크기의 인수를 입력하려면 다음과 같이 하면 됩니다.
가상화 기술에 대해서
CPU 의 속도 경쟁이 core 수를 늘리는 방향으로 전개 됨에 따라서 요즘에는 하나의 cpu 에 수십 개의 core 가 내장되기도 합니다. 이것은 수십 대의 컴퓨터가 하나의 cpu 에 들어있는 셈인데요. 이와 같은 고가의 장비에 하나의 OS 만 운영한다면 특정 작업이나 로드가 발생할 경우가 아니면 자원 활용 면에서 낭비되기 쉽습니다.
가상화는 이와 같은 유휴자원을 효율적으로 활용하기 위한 기술로 가상머신을 이용하면 시스템 로드에 따라서 신축적으로 하드웨어 자원을 이용할 수 있게 됩니다. 가상머신은 하나의 OS 가 실행되는 독립적인 머신과 같습니다. 그 아래 레이어에 hypervisor 가 위치하여 가상머신들의 리소스 ( cpu, memory, disk, network ... ) 를 컨트롤하고 스케줄 합니다. 이것은 마치 OS 가 각 프로세스의 리소스를 컨트롤하고 스케줄 하는 것과 비슷합니다.
가상화 레이어의 추가에 따른 손실을 줄이기 위해 다양한 방법들이 사용됩니다.
- 전가상화 ( full virtualization )
- 부분가상화 ( paravirtualization : para 는 alongside or partial 을 의미 )
- 하드웨어 서포트
가상머신 그러니까 guest OS 에 아무런 수정을 가하지 않는 것으로 guest OS 는 가상환경에서 ( hypervisor 위에서 ) 실행되고 있는 것을 모르는 것과 같습니다. 이와 같이 guest OS 를 실행하기 위해서는 hypervisor 가 필요한 모든 하드웨어 자원을 에뮬레이션 해야 됩니다.
전가상화 보다 빠르게 실행하기 위해서 guest OS 에 가상화 관련 패치를 하는 것입니다. 이렇게 하면 guest OS 가 직접 hypervisor 와 통신을 하므로 기존에 하드웨어 에뮬레이션으로 인한 복잡한 처리가 간단해집니다.
cpu 에서 가상화를 지원하면 hypervisor 코드가 간단해진다고 합니다. 그러니까 좀 더 빨리 실행될 수 있겠죠. cpu 외에 네크워트 카드 같은 주변장치에서도 가상화 지원을 하기도 합니다.
qemu 를 이용하면 x86 cpu 에서 arm cpu 실행파일과 OS 를 실행시킬 수 있습니다. 이것은 하드웨어와 cpu instructions 모두를 에뮬레이션 해야 되기 때문에 속도가 많이 느립니다. 만약에 guest OS 가 호스트와 같은 x86 이면 cpu instructions 변환 없이 바로 cpu 에서 실행시킬 수 있기 때문에 좀 더 빠르게 실행됩니다.
관심이 있으신 분은 여기 에서 파일을 받아서 테스트해보세요.
컨테이너
컨테이너는 원래 chroot 같은 프로세스 isolation 기술에서 발전한 것입니다. chroot 명령을 이용하면 root 디렉토리가 바뀌게 되므로 전혀 다른 시스템을 사용하는 것 같죠. 가상머신이 실제 독립적인 머신을 사용하는 효과를 주는 장점은 있지만 application 레이어에서 보면 불필요하게 OS 가 실행되는 단점도 있습니다.
예를 들어 리눅스 OS 를 사용하는 개발자가 독립적인 개발 환경을 셋팅하기 위해서 리눅스 가상머신에 웹서버, 데이터베이스를 설치해 사용한다면 이것은 호스트 리눅스 OS 위에 동일한 리눅스 OS 가 중복 실행되어 불필요하게 많은 리소스가 사용되는 것입니다. ( 물론 리눅스에서 windows OS 를 실행하려면 가상머신을 이용해야 합니다.)
컨테이너는 가상머신 OS 실행 없이 isolation 기술을 이용하여 실제 가상머신을 사용하는 효과를 제공합니다. 여기에는 cgroup 을 이용한 리소스 관리 ( cpu, memory, disk, network ... ), namespace 를 이용해서 hostname, process id, user id, network ... 등도 독립적으로 사용할 수 있으므로 실제 가상머신을 사용하는 것과 동일한 환경에서 application 을 운영할 수 있습니다.
다음은 unshare 명령을 이용해서 bash shell 을 독립적인 UTS namespace 에서 실행합니다.
$ hostname # 현재 hostname
EliteBook
$ sudo unshare --uts /bin/bash
$ lsns -t uts
NS TYPE NPROCS PID USER COMMAND
4026531838 uts 315 1 root /sbin/init splash
. . .
4026533257 uts 2 238698 root /bin/bash <----
$ hostname HelloHost # UTS namespace 는 독립적인 hostname 을 사용할 수 있게 해줍니다.
$ hostname
HelloHost
$ exit # bash 을 exit 하면
exit
$ hostname # 기존의 hostname 이 출력된다.
EliteBook
도커 컨테이너는 가상머신인가요? 프로세스인가요?
https://www.44bits.io/ko/post/is-docker-container-a-virtual-machine-or-a-process
도커 없이 컨테이너 만들기: https://www.youtube.com/watch?v=JexfNPWyeQA
현재 리눅스에서 많이 사용되는 컨테이너는 docker 와 lxc 기반의 lxd 인데요. 이것은 모두 리눅스 OS 에서 제공하는 컨테이너 기술을 이용하므로 사용방법이나 제공하는 기능들이 비슷한 점이 많습니다. docker 의 경우는 보통 application 컨테이너라고 하고 가능한 한 사이즈를 작게해서 하나의 application 을 제공하는 것을 목적으로 합니다. 반면에 lxd 의 경우는 machine 컨테이너라고 하고 가상머신과 동일한 환경을 제공하는 것을 목표로 합니다. 따라서 lxd 이미지를 다운받아 설치해보면 여기에는 기본적으로 init, systemd, syslog, cron 같은 프로세스들이 실행되고 있는 것을 볼 수 있으며 컨테이너 시작 시 자동으로 명령을 실행하고 싶으면 systemd 서비스를 등록하면 됩니다. 가상머신을 사용할 때와 마찬가지로 snapshot 도 할 수 있고 컨테이너를 네크워크를 통해 직접 서로 주고받을 수도 있으며 tar 파일로 export 하고 import 할 수도 있습니다.
컨테이너를 이용해 가상 머신에서 할 수 있는 것을 모두 할 수 있는 것은 아닙니다. 예를 들어 커널 모듈을 테스트하려고 한다면 컨테이너로는 안되고 가상머신을 이용해야 합니다. 일종에 유저모드 가상머신이 컨테이너라고 보면 됩니다.
lxd 컨테이너에 docker 설치해 사용하기
lxd 컨테이너는 system 컨테이너를 지향하기 때문에 docker 컨테이너를 설치해 사용할 수 있습니다. 예를 들어 docker swarm 을 테스트할 때 가상머신을 실행할 필요 없이 lxd 컨테이너를 사용하면 됩니다.
subicura 님의 docker swarm 실습 페이지 입니다.
https://subicura.com/2017/02/25/container-orchestration-with-docker-swarm.html
# lxd 설치 후 설정해야 될 사항 (default 는 default profile 을 말함)
$ lxc profile set default security.nesting "true"
$ lxc profile set default security.privileged "true"
$ lxc profile set default environment.TZ Asia/Seoul
$ lxc network set lxdbr0 ipv6.address none
$ lxc profile set default linux.kernel_modules overlay,nf_nat,ip_tables,ip6_tables,netlink_diag,br_netfilter,xt_conntrack,nf_conntrack,ip_vs,vxlan
# 생성된 컨테이너에 static ip 를 할당하려면
$ lxc stop mycontainer
$ lxc network attach lxdbr0 mycontainer eth0 eth0
$ lxc config device set mycontainer eth0 ipv4.address 10.215.19.10
$ lxc start mycontainer
# 현재 컨테이너를 이미지로 만들 때는 publish 명령을 사용합니다.
$ lxc snapshot mycontainer snap1
$ lxc publish mycontainer/snap1 --alias ubuntu-snap1
docker swarm 을 실습할 때 overlay 네트워크 용어가 나오는데 이것은 가상 네트워크를 말합니다.
하나의 물리 서버에 여러 개의 가상머신을 생성해 사용하듯이
하나의 물리 네트워크에( underlay ) 여러 개의 가상의 네트워크를( overlay ) 생성해서 사용하는 것입니다.
docker swarm 을 만들면 생성되는 ingress 네트워크는 특수한 overlay 네트워크인데
load balancing 기능을 가지고 있습니다.
가령 server1 에서 8080 포트로 서비스를 오픈하면 같은 ingress 네트워크에 속한
server2 에서는 localhost:8080 로 해도 server1 에 접속이 됩니다.
또는 server1 에서 server2:8080 로 해도 접속이 됩니다.
이것은 오픈한 8080 포트로 request 가 발생하면 IPVS 라는 네트워크 모듈이 ingress 네트워크에
속한 호스트 중 하나로 연결하기 때문입니다.
다음은 Joinc, JunYoung Park 님과 클쏭님의 도커 네트워크에 대한 설명입니다.
- 도커 네트워크
- docker network 구조
- docker0와 container network 구조
- container network 방식 4 가지
- container 외부 통신 구조
- 도커 bridge 네트워크 실습
(--link옵션은 deprecated 입니다. 사용자 정의 bridge 를 사용해야--name로 설정한 이름으로 접속할 수 있습니다. )
가상화를 사용하는 또 다른 목적은 소프트웨어와 하드웨어의 분리입니다. 가령 물리 서버가 고장날경우 기존에는 서버를 교체한 후에 다시 소프트웨어를 설치하고 환경 설정을 해주어야 하지만 가상화를 해두면 그럴 필요가 없게 됩니다. 왜냐하면 이미 가상머신 이라는 가상화 레이어 위에 소프트웨어 설치와 환경설정이 되어 있기 때문입니다. 이것은 또한 해당 서비스의 다른 서버로의 이동도 쉽게 이루어집니다. 그리고 네트워크 설정을 overlay 네트워크를 이용해 설정해두면 나중에 물리 네트워크가 어떻게 변경되던 상관이 없게 됩니다.
overlay 네크워크는 레이어를 한 단계 추가하는 것이기 때문에 그만큼 소프트웨어 처리 비용이 증가합니다. ( 네트워크 카드에 FPGA 나 CPU 를 장착해서 단순히 패킷만 전달하는 것이 아니라 특정 기능을 수행할 수 있게 만든 SmartNIC 이 개발되고 있습니다.)
이와 같은 가상화를 활용하는 추세는 네트워크 장비에서 소프트웨어와 하드웨어를 분리해 사용하는 SDN ( Software-Defined Networking ) 에서 부터 각 네트워크 기능을 가상화해 사용하는 NFV ( Network Functions Virtualization ) 에 이르기까지 다양하게 진행되고 있습니다.
Quiz
현재 남은 디스크 공간보다 사이즈가 큰 파일을 만들어서 사용할 수 있을까요?
가령 디스크 공간이 10G 뿐이 남지 않았어도 100G 크기의 파일을 생성해서 사용하는 것이 가능합니다. disk image 파일이나 database snapshot 같은 파일들은 처음에 10G, 20G 처럼 특정 크기의 파일을 생성한 후에 데이터가 쓰여지게 되는데요. 이와 같은 경우 데이터가 존재하는 부분을 제외하면 나머지 대부분의 영역은 빈 영역이 되게 됩니다. 따라서 filesystem 레벨에서 파일 사이즈는 100G 로 보여주되 실제 데이터가 존재하는 영역만 블록을 할당하고 나머지는 메타데이터 영역에 표시를 해서 read 가 발생할시 zero bytes 를 반환하도록 하는 것이 sparse file 입니다.
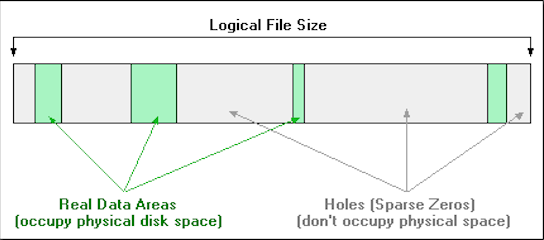
다음은 실제 디스크 여유 공간이 121G 인데 1000G 파일을 생성하는 예입니다.
$ df -h | sed -n '1p; /sda1/p' # 현재 디스크 여유 공간은 121G
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 234G 102G 121G 46% /
# 1000G 크기의 파일 생성
$ truncate -s 1000G disk.img # 또는 dd of=disk.img bs=1 seek=1000G count=0
# -s 옵션으로 제일 왼쪽에 보이는 0 이 실제 사용된 용량이고, 1000G 은 logical size 에 해당
$ ls -lsh disk.img
0 -rw-rw-r-- 1 mug896 mug896 1000G 2020-03-06 01:38 disk.img
$ stat disk.img # Size: 는 1000G 로 나오지만 실제 할당된 Blocks: 은 0 이다
File: disk.img
Size: 1073741824000 Blocks: 0 IO Block: 4096 regular file
Device: 801h/2049d Inode: 11046327 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ mug896) Gid: ( 1000/ mug896)
. . . .
$ df -h | sed -n '1p; /sda1/p' # 따라서 디스크 여유 공간도 그대로 121G 로 남아있다.
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 234G 102G 121G 46% /
이번에는 100M 크기의 disk.img 파일을 생성해서 mount 한 후에 파일을 생성해 보겠습니다.
$ truncate -s 100M disk.img
$ ls -lsh disk.img
0 -rw-rw-r-- 1 mug896 mug896 100M 2020-03-06 09:24 disk.img
$ mkfs.ext4 -q disk.img # disk.img 에 ext4 파일 시스템을 만듭니다.
$ ls -lsh disk.img # 파일 시스템이 생성되어 실제 디스크 사용량이 4.2M 가됨
4.2M -rw-rw-r-- 1 mug896 mug896 100M 2020-03-06 09:25 disk.img
$ stat disk.img
File: disk.img # 8512 개의 블록이 할당된 것을 볼 수 있습니다.
Size: 104857600 Blocks: 8512 IO Block: 4096 regular file
Device: 801h/2049d Inode: 11028268 Links: 1
. . . .
# mnt 디렉토리를 생성하고 -o loop 옵션을 이용해 disk.img 파일을 마운트 합니다.
# 그러면 /dev/loop? 장치가 disk.img 파일과 연결되고 mnt 디렉토리에 마운트 됩니다.
$ mkdir mnt && sudo mount -o loop disk.img mnt && sudo chmod 777 mnt
$ mount | grep disk.img
/home/mug896/disk.img on /home/mug896/mnt type ext4 (rw,relatime)
$ df -h | sed -n '1p; /mnt/p' # /dev/loop7 장치가 사용됨
Filesystem Size Used Avail Use% Mounted on
/dev/loop7 93M 72K 86M 1% /home/mug896/mnt
$ ls -l mnt
total 16
drwx------ 2 root root 16384 2020-03-06 09:25 lost+found/
# 다음은 마운트한 파티션이 No space left 가 될때까지 hello 파일에 random 문자를 쓰는것 입니다.
$ dd if=/dev/urandom of=mnt/hello bs=1M
dd: error writing 'mnt/hello': No space left on device
86+0 records in
85+0 records out
89956352 bytes (90 MB, 86 MiB) copied, 0.461591 s, 195 MB/s
$ ls -l mnt # 약 90M 크기의 파일이 생성되는 것을 볼 수 있습니다.
total 87864
drwx------ 2 root root 16384 2020-03-06 09:25 lost+found/
-rw-rw-r-- 1 mug896 mug896 89956352 2020-03-06 09:26 hello
$ ls -lsh disk.img # 실제 디스크 사용량도 86M 로 변경되었습니다.
86M -rw-rw-r-- 1 mug896 mug896 100M 2020-03-06 09:26 disk.img
# 이번에는 random 문자 대신에 zero bytes 를 쓰기합니다.
# 따라서 disk.img 파일의 대부분의 영역이 zero bytes 가 될것입니다.
$ dd if=/dev/zero of=mnt/hello bs=1M
dd: error writing 'mnt/hello': No space left on device
86+0 records in
85+0 records out
89956352 bytes (90 MB, 86 MiB) copied, 0.163433 s, 550 MB/s
$ ls -lsh disk.img
86M -rw-rw-r-- 1 mug896 mug896 100M 2020-03-06 10:09 disk.img
# sparse file 에서 디스크 사용량에 잡히지 않는 zero bytes 영역을 holes 이라고 하는데
# 이 명령은 파일에서 zero bytes 영역을 찾아서 holes 을 만들어 주는 역할을 합니다.
$ sudo umount mnt && fallocate -d disk.img
# 아직 disk.img 에는 90M 크기의 hello 파일이 있지만
# 실제 disk.img 파일이 차지하는 용량은 12M 가 되었습니다.
$ ls -lsh disk.img
12M -rw-rw-r-- 1 mug896 mug896 100M 2020-03-06 09:29 disk.img
위에서는 fallocate 명령을 사용하기 전에 먼저 dd if=/dev/zero ... 명령으로
disk.img 파일에 zero bytes 영역을 만들어 주었는데 다음과 같이 hello 파일을 삭제한 후에
zerofree 명령을 사용할 수도 있습니다.
# random 문자로 쓰기를한 hello 파일은 삭제가 되어도 해당 블록에는 데이터가
# 남아 있기 때문에 fallocate -d 명령을 사용해도 용량이 반환되지 않습니다.
# 이때는 먼저 zerofree 명령을 이용해 삭제된 파일의 기존 블록에 남아 있는 데이터를
# zero bytes 로 만들어 준후에 fallocate 명령을 사용하면 용량이 반환됩니다.
$ rm -f /mnt/hello && sudo umount mnt && zerofree disk.img && fallocate -d disk.img
이번에는 hole punching 을 해보겠습니다. hole punching 은 파일의 특정 영역에 hole 을 만들어서 디스크를 반환합니다. hole 을 만들수 있는 최소 크기는 filesystem 블록 크기인 4096 입니다.
$ dd if=/dev/urandom of=file1 bs=1M count=10 status=none # 10M 크기의 파일 생성
$ ls -lsh file1
10M -rw-rw-r-- 1 mug896 mug896 10M 2020-03-07 18:25 file1
# offset 2M 한 위치에서 length 3M 의 hole 을 만듭니다.
$ fallocate -p -o 2M -l 3M file1
$ ls -lsh file1 # 실제 디스크 사용량이 7M 가 되었습니다.
7.0M -rw-rw-r-- 1 mug896 mug896 10M 2020-03-07 18:25 file1
# offset 2M 에서 -40 한 위치에서부터 80 바이트를 추출해보면
# hole 이 만들어진 곳은 zero bytes 로 출력되는 것을 볼 수 있습니다.
$ dd if=file1 skip=$(( 1024**2 * 2 - 40 )) bs=1 count=80 status=none | od -va
0000000 @ F s dc3 - del fs _ 7 ! v n y } c ]
0000020 bel ] M 1 g 1 = y em dc4 p 7 gs ) $ e
0000040 ( g 6 + 2 m j j nul nul nul nul nul nul nul nul
0000060 nul nul nul nul nul nul nul nul nul nul nul nul nul nul nul nul
0000100 nul nul nul nul nul nul nul nul nul nul nul nul nul nul nul nul
0000120
이번에는 100M 용량의 disk.img 파일을 200M 로 늘리는 것을 해보겠습니다.
( disk.img 에 들어 있는 파일들도 유지가 됩니다. )
# 기존 100M 파일을 200M 로 늘려준다.
$ truncate -s 200M disk.img # 또는 dd of=disk.img bs=1 seek=200M count=0
# 기존 ext4 파일 시스템을 resize 합니다.
# truncate 단계없이 직접 e2fsck -f disk.img && resize2fs disk.img 200M 해도됨
$ e2fsck -f disk.img && resize2fs disk.img
e2fsck 1.45.3 (14-Jul-2019)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
. . .
$ sudo mount disk.img mnt && sudo chmod 777 mnt
# 다시 No space left 가 될때까지 쓰기를 해보면 200M 가까이 쓰기가 되는 것을 볼 수 있습니다.
$ dd if=/dev/urandom of=mnt/hello bs=1M
dd: error writing 'mnt/hello': No space left on device
176+0 records in
175+0 records out
184131584 bytes (184 MB, 176 MiB) copied, 0.888858 s, 207 MB/s
$ ls -lh mnt/hello
-rw-rw-r-- 1 mug896 mug896 176M 2020-03-06 10:51 mnt/hello
resize2fs 명령에 -M 옵션을 사용하면 disk.img 파일의 logical size 자체를 가능한 최소한의 사이즈로 만들어 줍니다.
이것은 sparse file 과는 관계없는 것으로 가령 disk.img 에 파일이 50M 가 있으면 50M 로 줄어듭니다.
$ ls -lsh disk.img # 현재 disk.img 파일의 logical size 는 100M
90M -rw-rw-r-- 1 mug896 mug896 100M 2020-03-07 08:47 disk.img
$ sudo mount disk.img mnt && sudo chmod 777 mnt
$ ls -l mnt
total 87864
drwx------ 2 root root 16384 2020-03-07 08:46 lost+found/
-rw-rw-r-- 1 mug896 mug896 89956352 2020-03-07 08:46 hello
$ rm -f mnt/hello && sudo umount mnt # 90M 가량의 hello 파일을 삭제
$ ls -lsh disk.img # disk.img 파일은 그대로 100M
90M -rw-rw-r-- 1 mug896 mug896 100M 2020-03-07 08:48 disk.img
$ e2fsck -f disk.img && resize2fs -M disk.img # -M 옵션을 사용
e2fsck 1.45.3 (14-Jul-2019)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
. . .
$ ls -lsh disk.img # disk.img 파일의 logical size 가 최소한의 크기인 7.3M 로 줄어듦
4.2M -rw-rw-r-- 1 mug896 mug896 7.3M 2020-03-07 08:48 disk.img
sparse file 기능을 사용하려면 filesystem 에서 해당 기능을 제공해야 하고 ( 요즘은 대부분 지원 ) 또한 사용하는 명령들에서도 지원을 해야 합니다. linux 에서는 기본적으로 cp, tar, cpio, rsync 같은 명령들에서
-S,--sparse옵션을 사용할 수 있습니다.