



 Move between spaces
Move between spaces
소문자로 된 명령은 copy 입니다.
목적지 기존 데이터는 삭제되고 source 내용이 dest 로 copy 됩니다.
대문자로 된 명령은 append 입니다.
먼저 newline 이 dest 에 append 되고 이어 source 내용이 dest 에 append 됩니다.
기본적으로 '
x' 명령을 제외하고 source 내용은 변하지 않습니다.
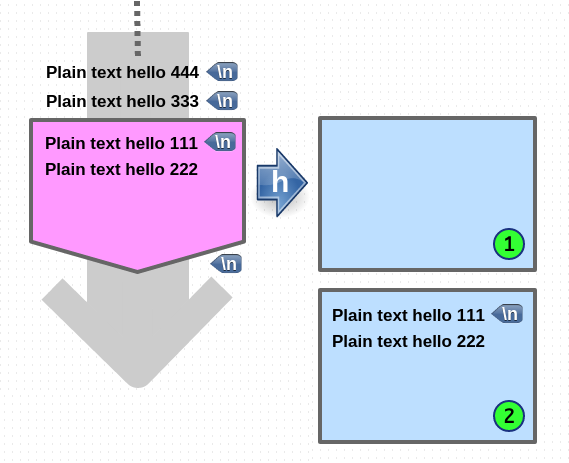
hold (copy)
1. 현재 hold space 에 있는 내용은 전부 삭제됩니다.
2. pattern space 에 있는 내용이 hold space 로 copy 됩니다.
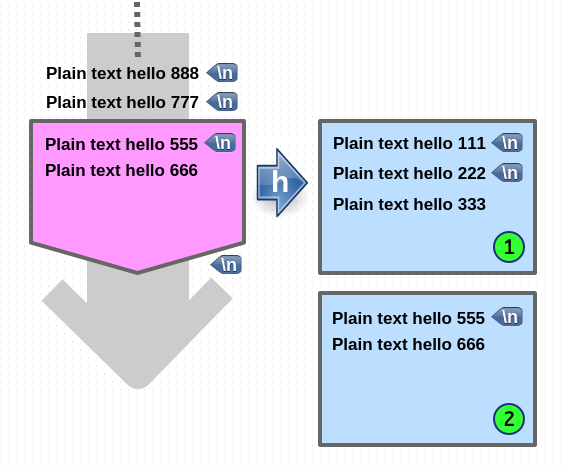
Hold (append)
1. 먼저 hold space 에 newline 을 append 합니다.
2. pattern space 에 있는 내용이 copy 되어 hold space 로 append 됩니다.
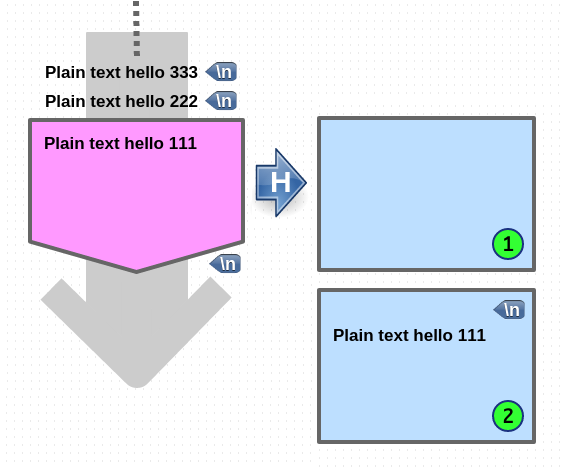
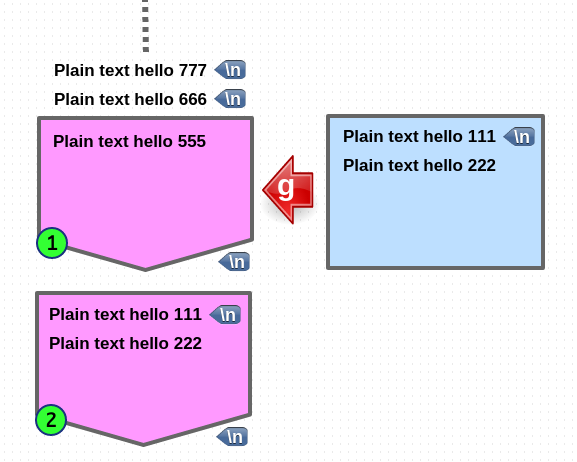
go to pattern space (copy)
1. 현재 pattern space 에 있는 내용은 전부 삭제됩니다.
2. hold space 에 있는 내용이 pattern space 로 copy 됩니다.
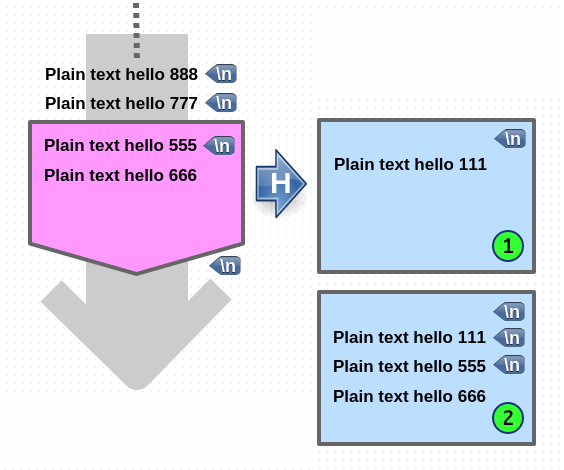
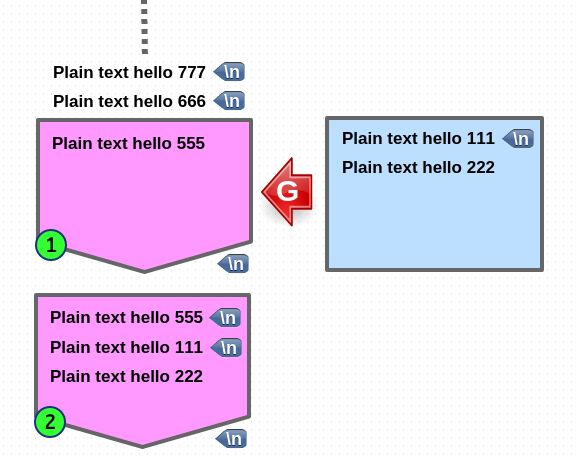
Go to pattern space (append)
1. 먼저 pattern space 에 newline 을 append 합니다.
2. hold space 에 있는 내용이 copy 되어 pattern space 로 append 됩니다.
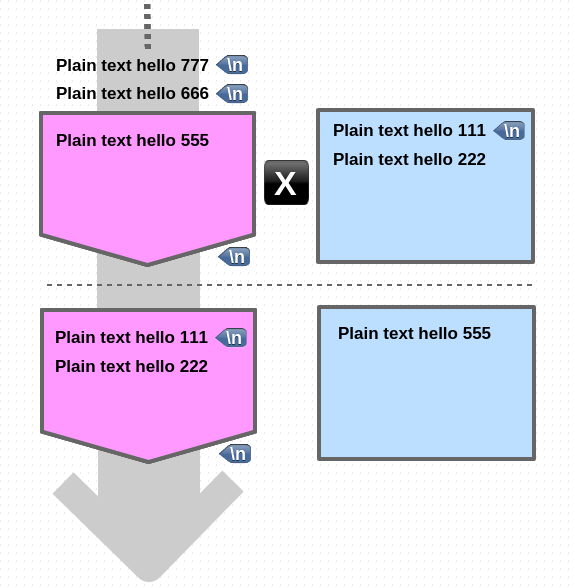
eXchange
1. pattern space 에 있는 내용과 hold space 에 있는 내용을 서로 맞바꿉니다.
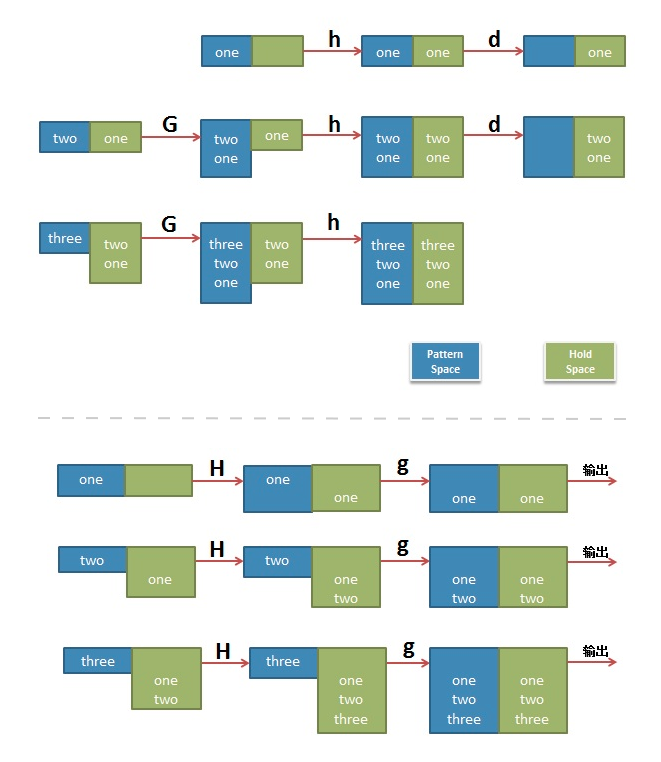
그림으로 보는 예제
예제 1
다음 예제는 어떤 명령의 실행 결과인데요.
md5sum 을 구해서 파일 사이즈와 함께 표시하는데 항상 출력이 다음과 같은 순서로 표시가 됩니다.
이것을 sed 를 이용해 파일명 -> gz -> bz2 순서로 변경하는 것입니다.
$ command ...
e805c26ff46c6e138e3cd198cff281ea 301 Packages.bz2
15bfecb2b041d5387aacdd32879e4e56 324 Packages
b97a7252f202566a1e5fdc5b50c2ffdf 283 Packages.gz
---------------------------------------------------
# 'n' 명령은 자동 출력 모드에서 pattern space 의 내용을 출력하므로 '-n' 옵션을 사용
$ command ... | sed -n 'h; n; N; G; p'
15bfecb2b041d5387aacdd32879e4e56 324 Packages
b97a7252f202566a1e5fdc5b50c2ffdf 283 Packages.gz
e805c26ff46c6e138e3cd198cff281ea 301 Packages.bz2
예제 2
다음은 docker hub 에서 특정 이미지의 tag list 를 조회해 sort 한 결과인데 이미지에 따라서
latest 가 다음과 같이 임의의 위치에 나타날 수 있습니다.
어떤 경우에서든 latest 를 항상 마지막에 표시하려면 어떻게 할까요?
$ docker-taglist alpine # latest 가 없는경우
latest 2.6 2.6 2.6
2.6 2.7 2.7 2.7
2.7 3 3 3
3 3.1 3.1 3.1
3.1 3.2 3.2 3.2
3.2 3.3 3.3 3.3
3.3 latest 3.4 3.4
3.4 3.4 3.5 3.5
3.5 3.5 3.6 3.6
3.6 3.6 latest
--------------------------------------------------------------
# 입력 라인이 'latest' 가 아닐 경우 출력한 후 :X 레이블로 branch 합니다.
/^latest$/!{p; bX};
# 입력 라인이 'latest' 일 경우는 hold space 에 저장합니다.
h;
# 마지막 라인일 경우 hold space 의 내용을 pattern space 로 가져오는데
# 이때 값이 없는 경우가 있을 수 있으므로 /^$/! 로 체크하여 프린트합니다.
${g; /^$/!p}'
$ cat taglist | sed -n '/^latest$/!{p; bX}; h; :X ${g; /^$/!p}'
예제 3
/usr/include/elf.h 파일 내용을 보면 여러개의 typedef struct 이 있는데요.
그중에서 Elf64_Ehdr 부분만 추출합니다.
# "typedef struct" 을 포함하는 라인을 만나면 hold space 로 이동하고 식의 끝으로 branch 합니다.
# 이때 기존에 hold space 에 내용이 있었다면 삭제됩니다.
/typedef struct/{h;b}
# 이후부터는 라인을 hold space 에 계속 append 합니다.
H
# "Elf64_Ehdr;" 가 포함된 라인을 만나면 hold space 에 있는 내용을 pattern space 로 옮긴 후
# 프린트하고 종료합니다.
/Elf64_Ehdr;/{g;p;Q}/
$ sed -n '/typedef struct/{h;b}; H; /Elf64_Ehdr;/{g;p;Q}' /usr/include/elf.h
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf64_Half e_type; /* Object file type */
Elf64_Half e_machine; /* Architecture */
Elf64_Word e_version; /* Object file version */
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags; /* Processor-specific flags */
Elf64_Half e_ehsize; /* ELF header size in bytes */
Elf64_Half e_phentsize; /* Program header table entry size */
Elf64_Half e_phnum; /* Program header table entry count */
Elf64_Half e_shentsize; /* Section header table entry size */
Elf64_Half e_shnum; /* Section header table entry count */
Elf64_Half e_shstrndx; /* Section header string table index */
} Elf64_Ehdr;
다음은 -z 옵션을 이용해 전체 파일을 읽어들인 후 regex 을 활용하는 방법입니다.
$ sed -z -rn 's/.*(typedef struct\n.+} Elf64_Ehdr;\n).*/\1/p' /usr/include/elf.h
예제 4
다음과 같이 AAA 뒤에 숫자 데이터가 이어지는데요.
이것을 한개의 라인으로 만드는것 입니다.
# 데이터 내용
AAA
1
34
AAA
5
32
61
17
AAA
71
4
15
...................
$ sed -En '
/AAA/{
:X
x # `x` 명령으로 hold space 내용과 pattern space 내용을 교환합니다.
s/\n/ /g # newline 을 space 로 변경하여 한 줄로 만듭니다.
p # 내용을 프린트하고
b # 명령 사이클의 END 로 분기합니다.
}
H # AAA 와 매칭이 되지 않은 경우는 `H` 명령으로 hold space 에 append 합니다.
$bX # 마지막 라인일 경우 :X 로 분기하여 hold space 에 있는 내용을 프린트합니다.
' file
AAA 1 34
AAA 5 32 61 17
AAA 71 4 15
예제 5
필드가 space 로 분리되어 있는 레코드에서 /config 과 /service 필드를 추출합니다.
그런데 여기서 문제는 필드의 위치나 순서가 정해져 있지가 않습니다.
# 데이터 내용
build 345 /config:launcher.mxres /nickname:prod /service:session
auto 4986 /nickname:deal /service:engine /config:launcher5.mxres
build 912 /config:launcher_binary.mxres /service:scanner /nickname:input
.........................................................................
$ sed -E '
h # 먼저 원본 라인을 hold 하여 복사
s#.*(/config:[^ ]+).*#\1# # /config 값을 추출한 후 `H` 명령으로 hold space 에 append.
H;g # 현재 pattern space 는 /config 값만 남고 삭제된 상태이므로
# `g` 명령을 이용해 hold space 값을 pattern space 로 복사
s#.*(/service:[^ ]+).*#\1# # 위와 같은 방법으로 /service 값 추출
H;g # `g` 명령을 이용해 hold space 값을 pattern space 로 복사
s#.*\n(.*)\n(.*)#\1 \2# # 현재 pattern space 에는 원본 라인과 /config, /service
# 3개의 라인이 존재하므로 /config, /service 값만 추출
' file
/config:launcher.mxres /service:session
/config:launcher5.mxres /service:engine
/config:launcher_binary.mxres /service:scanner
Quiz
앞서 regex 메뉴에서 lazy 매칭을 하는 방법에 대해서 알아보았는데요. 단일 문자가 아니라 특정 스트링을 lazy 매칭해서 삭제하려면 어떻게 할까요?
# .* 는 greedy 하므로 마지막 foo 단어까지 삭제가 된다.
$ echo "111 foo 222 foo 333" | sed -E 's/.*foo//'
333
$ echo "111 foo 222 foo 333" | sed -E 'h; s/(foo).*$/\1/; G; s/^([^\n]+)\n\1//'
222 foo 333
1. h; 먼저 입력값을 hold space 에 저장해 놓습니다.
2. s/(foo).*$/\1/ 식으로 greedy 매칭을 뒤에서 부터하면 pattern space 에는
111 foo 만 남게됩니다.
3. G 명령으로 hold space 에 저장해 놓은 원본값을 pattern space 에 append 합니다.
111 foo
111 foo 222 foo 333
4. s/^([^\n]+)\n\1// (여기서 \1 은 ([^\n]+) 매칭된 값과 동일한 값이 됩니다.)
식을 이용해 pattern space 에서 앞부분을 삭제하면 222 foo 333 만 남게됩니다.
-------------------------------------------------------
# perl 에서는 .*? 를 이용해 lazy 매칭을 할 수 있습니다.
$ echo "111 foo 222 foo 333" | perl -pe 's/.*?(foo)//'
222 foo 333
다음은 FOO 에서부터 BAR 까지 lazy 매칭하여 XXX 로 치환하는 것입니다.
$ echo sss FOO uuu BAR nnn FOO ccc BAR rrr |
sed 's/BAR/\a/g; s/FOO[^\a]*\a/XXX/; s/\a/BAR/g'
sss XXX nnn FOO ccc BAR rrr
1. 먼저 BAR 를 \a 문자로 모두 치환합니다.
2. 그다음 FOO 에서부터 \a 문자 까지를 XXX 값으로 치환합니다.
3. 마지막으로 남은 \a 문자를 다시 BAR 로 모두 치환합니다.
# 만약에 FOO 나 BAR 단어에 regex 이 포함될 경우는 다음과 같이하면 됩니다.
$ echo "sss FXO uuu BXR nnn FYO ccc BYR rrr" |
sed -E 's/(B[A-Z]R)/\a\1/g; s/F[A-Z]O[^\a]*\aB[A-Z]R/XXX/; s/\a//g'
sss XXX nnn FYO ccc BYR rrr
------------------------------------------------------------------------
$ echo "sss FOO uuu BAR nnn FOO ccc BAR rrr" | perl -pe 's/FOO.*?BAR/XXX/'
sss XXX nnn FOO ccc BAR rrr
이번에는 BAR 쪽 뿐만 아니라 FOO 쪽도 lazy 매칭을 적용하는 것입니다.
# FOO 쪽은 lazy 매칭이 적용되지 않아 FOO 두개가 모두 삭제된다.
$ echo sss FOO uuu FOO w BAR nnn FOO ccc BAR rrr | perl -pe 's/FOO.*?BAR/XXX/'
sss XXX nnn FOO ccc BAR rrr
$ echo sss FOO uuu FOO w BAR nnn FOO ccc BAR rrr |
sed 's/FOO/\a/g; s/BAR/\v/g; s/\a[^\a\v]*\v/XXX/; s/\a/FOO/g; s/\v/BAR/g'
sss FOO uuu XXX nnn FOO ccc BAR rrr