Regex
문자를 다루는 Regular expression 은 소프트웨어 공학에서 제일 중요하고 기초가 되는 부분입니다. 쉘에서 명령을 실행했을때 발생하는 출력도 문자고, 컴파일러가 파싱을 위해 읽어들이는 소스코드도 프로그래머가 작성한 문자들이기 때문입니다. Regular expression 은 규칙이 있는 표현식이란 의미로 특정 메타문자를 이용해 규칙을 표현해 주면 해당 규칙에 맞는 스트링을 매칭할 수 있습니다. regex 는 보통 3가지로 분류가 됩니다. BRE( Basic Regular Expressions ), ERE( Extended Regular Expressions ), PRE( Perl Regular Expressions ) 인데요. 기본적으로 사용되는 문법은 같은데 기능은 PRE 가 제일 많습니다. 당연히 perl 에서 사용되는데 grep 같은 명령에서도 툴 특성상 부분적으로 제공하고 있습니다. 하지만 보통 대부분의 명령에서 제공하는 것은 BRE, ERE 입니다. 굳이 PRE 까지 기능을 제공하지 않아도 대부분 문제 해결이 되기 때문이기도 하겠습니다.
regex 이 암호문 같다고 싫어하는 사람이 많은데 생각보다 중요하고 많은 능력을 가지고 있습니다.
입력값을 파싱하는데 수십줄 소요되는 코드를 regex 한, 두개로 처리하는 사람도 있습니다.
Regular Expressions 을 테스트할 수 있는 사이트 : https://regex101.com/
BRE, ERE
예전에는 ERE 가 BRE 에 비해 좀더 확장된 기능을 가지고 있었다고 하는데 지금은 기능상의 차이는 없고 단지 syntax 만 다르다고 합니다.
?, +, |, ( ), { }
이 문자들은 regex 에서 특수한 기능을 하는 메타문자 들인데요. 이 문자들을 기본적으로 escape 해서 사용하면 BRE 이고 그렇지 않으면 ERE 입니다.
# BRE
$ echo AA22-CC1234 | sed -n 's/[A-Z]\{2\}[0-9]\+-\([A-Z]\{2\}[0-9]*\)/\1/p'
CC1234
# ERE
$ echo AA22-CC1234 | sed -En 's/[A-Z]{2}[0-9]+-([A-Z]{2}[0-9]*)/\1/p'
CC1234
------------------------------------
# BRE
$ echo ABCD | sed -n '/CC\?\|EE\?/p'
ABCD
# ERE
$ echo ABCD | sed -En '/CC?|EE?/p'
ABCD
위 예제에서는 ERE 가 간결해 보이지만 만약에 스트링에
위의 regex 메타문자가 많이 포함되어 있다면 BRE 로 작성하는게 더 식이 간단해질 수 있습니다.
ERE 에서는 모두 escape 해야 되니까요.
sed 는 default 가 BRE 입니다.
그러므로 ERE syntax 를 사용하기 위해선 다음과 같이 -E 또는 -r 옵션을 사용해야 합니다.
# BRE 가 더 간단하다.
$ echo '{AA22}+(CC1234)' | sed -n '/{AA22}+(CC1234)/p'
{AA22}+(CC1234)
# ERE 는 모두 escape 해야 한다.
$ echo '{AA22}+(CC1234)' | sed -En '/\{AA22\}\+\(CC1234\)/p'
{AA22}+(CC1234)
$ sed '...' # BRE (default)
$ sed -E '...' # ERE
$ sed -r '...' # ERE
BRE, ERE 공통 문자
다음 문자들는 공통적으로 escape 하지 않고 사용하는 regex 메타문자 인데요.
그러므로 일반 텍스트 문자로 사용하려면 BRE, ERE 모두에서 \ 를 이용해 escape 해야 합니다.
[ ]와{ }를 escape 할 때는 첫 번째 문자만 하면 됩니다.
^, $, *, ., [ \
# BRE (escape 해서 사용)
$ echo '^*.\[]$' | sed 's/\^\*\.\\\[]\$/xxx/'
xxx
# ERE (escape 해서 사용)
$ echo '^*.\[]$' | sed -E 's/\^\*\.\\\[]\$/xxx/'
xxx
Character Classes and Bracket Expressions
[ ] 표현식은 안에 있는 문자들 중에 하나를 의미합니다.
그러므로 다음과 같은 경우 gray or grey 단어가 blue 로 치환됩니다.
sed 's/gr[ae]y/blue/'
- 기호를 사용해서 두 문자를 연결할 수 있는데 이때는 사이에 존재하는 모든 문자를 포함합니다.
gr[a-d]y : gray grby grcy grdy
문자들을 비슷한 의미를 가진 그룹으로 나누어놓은 것이 character classes 입니다.
[[:alnum:]] 의미는 [ ] 표현식 내에서 [:alnum:] 이라는 클래스가 사용되어
결과적으로 [A-Za-z0-9] 의미를 가지게 됩니다.
따라서 [[:upper:][:digit:]] 의 의미는 [A-Z0-9] 와 같게 됩니다.
| Class | Represented | Description |
|---|---|---|
| [[:alnum:]] | [A-Za-z0-9] |
Alphanumeric characters |
| [[:alpha:]] | [A-Za-z] |
Alphabetic characters |
| [[:lower:]] | [a-z] |
Lower-case alphabetic characters |
| [[:upper:]] | [A-Z] |
Upper-case alphabetic characters |
| [[:digit:]] | [0-9] |
Numeric characters |
| [[:xdigit:]] | [0-9a-fA-F] |
Hexadecimal digit characters |
| [[:space:]] | [ \t\n\v\f\r] |
All whitespace chars (form feed \x0c) |
| [[:blank:]] | [ \t] |
Space, tab only |
| [[:punct:]] | [!@#$%^&*(){}[]...] |
키보드에 있는 숫자, 대,소문자 빼고 모든 문자 |
| [[:graph:]] | [!-~] |
Printable and visible characters (ASCII 테이블에서 ! 부터 ~ 까지) |
| [[:print:]] | [ -~] |
Printable (non-Control) characters (ASCII 테이블에서 space 부터 ~ 까지) |
| [[:cntrl:]] | [\x00-\x19\x7F] |
Control characters |
[[:graph:]]와[[:print:]]는 space 를 포함하고 안 하고 차이.
[ ] 표현식 에서 - 를 일반 문자로 사용할 때는 두 문자 사이에 위치하지 않게
처음이나 마지막에 위치시키면 되고 [, ] 문자는 처음에 위치시키면 됩니다.
# 'allow-all' 'vm-process-priority' 와 같은 소문자와 '-' 문자로 이루어진 단어 매칭
[[:lower:]-]+ or [a-z-]+
# 전달된 스트링에서 ']' or '[' or '@' 문자를 삭제
$ echo '[@foo]' | sed 's/[][@]//g'
foo
# 전달된 스트링이 ']' or '[' or '[:alnum:]' 으로 구성되면 매칭
$ echo '-t[imestamp]' | sed -En '/^-[][[:alnum:]]+$/p'
-t[imestamp
기본적으로 [ ] 표현식 안에서는 *, ?, ., | 같은 regex 메타문자를 escape 하지 않아도 됩니다.
# * + ? [ ] { } ( ) | . ^ $ 모두 escape 하지 않아도된다.
$ echo '*+?[]{}()|.^$' | sed -En '/[][{}()*+?|.^$]/p'
*+?[]{}()|.^$
logical NOT 을 나타내는 ^
[ ] 표현식의 맨앞에 ^ 를 위치시키면 logical NOT 의 역할을 합니다.
# '\n' 을 제외한 모든 문자 (newline 만 아니면 매칭 성공)
[^\n]
# 숫자를 제외한 모든 문자 (숫자만 아니면 매칭 성공)
[^[:digit:]] or [^0-9]
# ']', '[', '|', '-' 문자가 아니면 매칭 성공
[^][|-]
Regular expression Extensions
이 기능은 BRE, ERE 모두에서 사용할 수 있습니다.
소문자와 대문자가 같이 있는데 대문자는 소문자의 logical NOT 과 같습니다.
이 확장 기능은 [ ] 에서는 사용할 수 없습니다.
다시 말해서 [\w] 는 \, w 두 문자를 나타냅니다.
\s, \S
\s 는 [[:space:]] 를 \S 는 [^[:space::]] 를 나타냅니다.
\w, \W
\w 는 [[:alnum:]_] 를 나타냅니다. 즉 [:alnum:] 클래스에 _ 가 추가된 것입니다.
(- 는 포함되지 않습니다.)
\W 는 [^[:alnum:]_] 을 나타냅니다.
\b, \B
word boundary 를 나타냅니다.
# \b 의 경우
$ echo 'abc %-= def.' | sed 's/\b/X/g'
XabcX %-= XdefX.
# \B 의 경우
$ echo 'abc %-= def.' | sed 's/\B/X/g'
aXbXc X%X-X=X dXeXf.X
\<, \>
\< 는 word boundary 인데 word 의 시작 부분을, \> 는 word 의 끝부분을 나타냅니다.
# '\<' 의 경우
$ echo "abc %-= def." | sed 's/\</X/g'
Xabc %-= Xdef.
# '\>' 의 경우
$ echo "abc %-= def." | sed 's/\>/X/g'
abcX %-= defX.
Subexpressions and Back-references
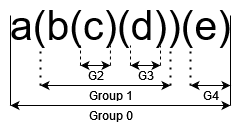
regex 에서 ( ) 를 하면 subexpression 이 됩니다.
이 subexpression 은 { }, +, * 와 같은 수량 한정자와 같이 사용될 수 있습니다.
$ echo "aaa@bbb@" | sed -En '/^\w+@$/p'
$ echo "aaa@bbb@" | sed -En '/^(\w+@){2}$/p'
aaa@bbb@
$ echo "aaa@bbb@" | sed -En '/^(\w+@)+$/p'
aaa@bbb@
# 중복 매칭 구하기, 'sed' 단어가 2번 이상 포함될 경우만 프린트
$ echo "111sed22sss333" | sed -En '/(sed.*){2,}/p'
$ echo "111sed22sed333" | sed -En '/(sed.*){2,}/p'
111sed22sed333
# sed 두 단어가 붙어 있을 수도 있으므로 '.*' 를 사용
$ echo "111sedsed333" | sed -En '/(sed.*){2,}/p'
111sedsed333
또한 ( ) 에서 OR 연산자를 사용할 수 있습니다.
$ echo 'AA11 AA22 AA33 AA44 AAAA' | sed -E 's/AA(11|22|[^0-9]{2})/XX/g'
XX XX AA33 AA44 XX
# %pK 는 놔두고 %p 만 %pK 로 변경
$ echo '%pK %p-%p' | sed -E 's/%p([^K])/%pK\1/g'
%pK %pK-%p
$ echo '%pK %p-%p' | sed -E 's/%p([^K]|$)/%pK\1/g'
%pK %pK-%pK
---------------------------------------------------------------------
# 다음 두 식은 같은 결과를 같습니다.
# 참고로 [ ] 안에서 '.' 문자를 사용할땐 escape 하지 않아도 되는걸 알 수 있습니다.
$ echo '__123-45.67__' | sed -En '/^(0|1|2|3|4|5|6|7|8|9|\.|_|-)+$/p'
__123-45.67__
$ echo '__123-45.67__' | sed -En '/^[0-9._-]+$/p'
__123-45.67__
( ) 를 하면 back-reference 를 위한 번호가 매겨지고 \1 \2 \3 와 같은 형태로 참조할 수 있습니다.
$ echo "aaa@bbb@ccc" | sed -E 's/(\w+)@(\w+)@(\w+)/\1/'
aaa
$ echo "aaa@bbb@ccc" | sed -E 's/(\w+)@(\w+)@(\w+)/\2/'
bbb
$ echo "aaa@bbb@ccc" | sed -E 's/(\w+)@(\w+)@(\w+)/\3/'
ccc
이 back-reference 번호는 regex 에서도 사용될 수 있습니다.
# 여기서 '\1' 은 (\w+) 를 나타내는 것이 아니고 매칭 된 결과 그러니까 aaa 를 나타냅니다.
# aaa 와 ccc 는 틀리므로 매칭이 안됨
$ echo "aaa@bbb@ccc" | sed -En '/(\w+)@\w+@\1/p'
# aaa 와 aaa 는 매칭이 되므로 내용이 프린트가 된다
$ echo "aaa@bbb@aaa" | sed -En '/(\w+)@\w+@\1/p'
aaa@bbb@aaa
# 이번에는 word boundary 로 'sed' 단어가 2번 이상 포함될 경우만 프린트
$ echo "111 sedsed 33" | sed -En '/(\bsed\b).*\1/p'
$ echo "111 sed sed 33" | sed -En '/(\bsed\b).*\1/p'
111 sed sed 33
( ) 는 nesting 해서 사용할 수 있습니다. 바깥쪽 괄호가 작은 번호가 됩니다.
$ echo "aaa@bbb@ccc" | sed -E 's/(((\w+)@\w+)@\w+)/\1/'
aaa@bbb@ccc
$ echo "aaa@bbb@ccc" | sed -E 's/(((\w+)@\w+)@\w+)/\2/'
aaa@bbb
$ echo "aaa@bbb@ccc" | sed -E 's/(((\w+)@\w+)@\w+)/\3/'
aaa
regex 로 매칭된 전부를 나타내는 & 문자
$ echo '111 AB 222 CD 333' | sed -E 's/.*/X&X/'
X111 AB 222 CD 333X
$ echo '111 AB 222 CD 333' | sed -E 's/[A-Z]+/X&X/'
111 XABX 222 CD 333
$ echo '111 AB 222 CD 333' | sed -E 's/[A-Z]+/X&X/g'
111 XABX 222 XCDX 333
$ echo '111 AB 222 CD 333' | sed -E 's/[A-Z]+.*/X&X/'
111 XAB 222 CD 333X
* 와 + 는 greedy 하므로 주의가 필요하다.
regex 에서 *, + 를 이용하여 매칭을 시도할 때 한가지 문제점이 있는데요.
가령 아래와 같은 라인이 있을 때 /AA.*AA/ or /AA.+AA/ 로 매칭을 시도하면
어디까지 매칭을 해야 되는가 하는 것입니다.
AA 111 AA 222 AA 333 AA # lazy matching
^^^^^^^^^
AA 111 AA 222 AA 333 AA # greedy matching
^^^^^^^^^^^^^^^^^^^^^^^
regex 에서는 기본적으로 두번째 greedy (longest) matching 을 합니다.
따라서 regex 를 작성할 때 다음과 같은 경우 주의할 필요가 있습니다.
# 숫자 부분을 추출하려고 하는데 마지막 문자만 표시된다.
$ echo "abc123" | sed -En 's/.*([0-9]+)/\1/p'
3
# 첫 번째 'img' 태그를 삭제하려고 하는데 '<html>' 만 남고 모두 삭제된다.
$ echo '<html><img src="file1.png">abc<img src="file2.png"></html>' |
sed -En 's/<img.*>//p'
<html>
# 앞쪽의 'aa=11,xx=00,bb' 를 'cc' 로 변경하려고 하는데 마지막 'bb' 까지 매칭이 된다.
$ echo 'aa=11,xx=00,bb=22,aa=33,yy=00,bb=44' | sed -E 's/aa.*bb/cc/'
cc=44
sed 에서 lazy matching 을 하려면 다음과 같이 하면됩니다.
$ echo "abc123" | sed -En 's/[^0-9]*([0-9]+)/\1/p'
123
$ echo '<html><img src="file1.png">abc<img src="file2.png"></html>' |
sed -En 's/<img[^>]*>//p'
<html>abc<img src="file2.png"></html>
$ echo 'aa=11,xx=00,bb=22,aa=33,yy=00,bb=44' | sed -E 's/aa[^b]*bb/cc/'
cc=22,aa=33,yy=00,bb=44
# 다음은 앞쪽이 아니라 뒤쪽을 cc 로 바꿀경우
# 마지막 '=44' 는 regex 매칭에는 포함되지 않은 hidden 이다.
$ echo 'aa=11,xx=00,bb=22,aa=33,yy=00,bb=44' | sed -E 's/(.*)aa.*bb/\1cc/'
aa=11,xx=00,bb=22,cc=44
# 다음의 경우는 두 개의 greedy (.*) 가 사용되었는데요.
# 결과적으로 앞쪽이 먼저 처리되는 것을 볼수 있습니다.
$ echo 'aa=11,xx=00,bb=22,aa=33,yy=00,bb=44' | sed -E 's/aa.*bb(.*)/cc\1/'
cc=44
특정 스트링을 lazy 매칭하는 방법은 이곳 에서 볼 수 있습니다.
* 와 + 의 backtracking 기능
* 와 + 는 임의의 수량을 나타내기 때문에 만약에 다음에오는 값이 매칭이 안될경우
매칭하기 위해 다시 뒤로 갈수가 있습니다. 일종의 고급 기능으로 특정 상황에서
유용하게 사용될 수 있습니다.
$ echo 'model <dell,847483992,16G> AMD' | sed -En 's/<[^>]*/</p'
model <> AMD
$ echo 'model <dell,847483992,16G> AMD' | sed -En 's/<[^>]*,/</p' # "," 추가
model <16G> AMD
1. 먼저 <[^>]* 식에 의해서 <dell,847483992,16G 까지 매칭이 됩니다.
2. 그런데 <[^>]* 식 뒤에 "," 가 와서 "> AMD" 와 매칭이 안되므로 매칭이 될때까지
다시 backtracking 을 하게되어 <dell,847483992, 에서 매칭이 되게 됩니다.
다음은 Go 언어에서 사용되는 함수 형식인데 backtracking 을 이용해 함수명을 추출하는 예입니다.
func TeeReader(r Reader, w Writer) Reader { ...
func (l *LimitedReader) Read(p []byte) (n int, err error) { ...
func Print[T1 any, T2 any](a T1, b T2) { ...
$ echo 'func (l *LimitedReader) Read(p []byte) (n int, err error) { ...' |
sed -En 's/^func[^{]* (\w+)[[(].*/\1/p'
Read
1. 먼저 ^func[^{]* 식에 의해 func 에서부터 { 문자 앞부분까지 매칭이 됩니다.
2. 그다음 ^func[^{]* 식에 이어서 " (\w+)[[(].*" 이 오는데 "{" 와는 매칭이 안되죠.
3. 따라서 매칭이 될때까지 backtracking 을 하면 ... Read( 에서 매칭이 되게 됩니다.
.* 와 .+ 는 greedy 하지만 구분자로 사용되는 , 문자가 사이에 존재하면
매칭이 되어 필드값을 추출할 수가 있습니다.
$ echo "111,222,333,444" | sed -En 's/(.*),(.*),(.*),(.*)/\1:\2:\3:\4/p'
111:222:333:444
1. 첫번째 (.*) 식에 의해 111,222,333,444 전체가 매칭이 됩니다.
2. 그런데 다음에 "," 가 오므로 backtracking 을 하면 111,222,333, 에서 매칭이 됩니다.
3. 두번째 (.*) 식에 의해 앞서 매칭된 111,222,333, 와 444 가 매칭이 됩니다.
4. 그런데 다음에 또 "," 가 오므로 매칭이 실패하게 되어 첫번째 와 두번째 (.*) 가 모두
다시 backtracking 을 하게 되어 첫번째는 111,222, 에서 매칭이 되고 두번째는
333, 에서 매칭이 되게 됩니다.
5. 세번째 (.*) 식에 의해 앞서 매칭된 111,222, 와 333, 와 444 가 매칭이 됩니다.
6. 그런데 다음에 또 "," 가 와서 매칭이 실패하게 되어 ...
( 기본적인 로직이 이렇다는 것이고 실제는 빠른 처리를 위해 최적화가 이루어집니다.)
regex 를 이용한 추출
입력값에서 특정 스트링만 추출할 때는 grep -o 나awk 명령을 사용하는 것이
편리하지만 sed 에서도 regex 을 이용해 추출을 할 수가 있습니다.
# 다음은 스트링에 숫자가 포함되어 있을 경우 특정 위치의 숫자만 추출합니다.
$ echo "aaa123bbb456ccc789ddd" | sed -E 's/([a-z]+([0-9]+)).*/\2/' # 첫번째 숫자
123
$ echo "aaa123bbb456ccc789ddd" | sed -E 's/([0-9]+).*|./\1/g'
123
$ echo "aaa123bbb456ccc789ddd" | sed -E 's/([a-z]+([0-9]+)){2}.*/\2/' # 두번째 숫자
456
$ echo "aaa123bbb456ccc789ddd" | sed -E 's/([a-z]+([0-9]+)){3}.*/\2/' # 세번째 숫자
789
----------------------------------------------------------------------
# "숫자%" 로 구성된 항목만 추출
$ df -h | sed -E 's/([0-9]+%)|./\1/g'
0%
1%
49%
1%
$ echo '/dev/sda1 511% 7.1M 504M 24% /boot/efi' |
sed -E 's/([0-9]+% )|./\1/g'
511% 24%
1. "/dev/sda1 " 앞부분은 ([0-9]+% ) 식과 매칭이 되지 않으므로 "." 와 매칭이 되어 출력에서 제외가 됩니다.
2. "511% " 는 ([0-9]+% ) 식과 매칭이 되어 \1 에의해 출력에 남게 됩니다.
3. "7.1M 504M " 부분도 ([0-9]+% ) 식과 매칭이 되지 않으므로 "." 와 매칭이 되어 출력에서 제외가 됩니다.
4. "24% " 는 ([0-9]+% ) 식과 매칭이 되어 \1 에의해 출력에 남게 됩니다.
5. "/boot/efi" 부분도 ([0-9]+% ) 식과 매칭이 되지 않으므로 "." 와 매칭이 되어 출력에서 제외가 됩니다.
# 다음은 "[숫자]" or "<숫자>" 형태만 추출합니다.
$ echo "aa [12] bb <34> cc [5X6] dd <78> ee [99] ff" |
sed -E 's/(\[[0-9]+] |<[0-9]+> )|./\1/g'
[12] <34> <78> [99]
{ } 수량 한정자
* 는 {,} 와 같고 + 는 {1,} 과 같습니다.
$ echo "XYXYXY12345" | sed -E 's/^(XY)*/ZZZ/'
ZZZ12345
$ echo "XYXYXY12345" | sed -E 's/^(XY){,}/ZZZ/'
ZZZ12345
$ echo "XYXYXY12345" | sed -E 's/^(XY)+/ZZZ/'
ZZZ12345
$ echo "XYXYXY12345" | sed -E 's/^(XY){1,}/ZZZ/'
ZZZ12345
$ echo "12345" | sed -E 's/^(XY)*/ZZZ/'
ZZZ12345
$ echo "12345" | sed -E 's/^(XY){,}/ZZZ/'
ZZZ12345
$ echo "12345" | sed -E 's/^(XY)+/ZZZ/'
12345
$ echo "12345" | sed -E 's/^(XY){1,}/ZZZ/'
12345
? 는 {,1} 와 같습니다.
$ echo "XY12345" | sed -E 's/^(XY)?/ZZZ/'
ZZZ12345
$ echo "XY12345" | sed -E 's/^(XY){,1}/ZZZ/'
ZZZ12345
$ echo "12345" | sed -E 's/^(XY)?/ZZZ/'
ZZZ12345
$ echo "12345" | sed -E 's/^(XY){,1}/ZZZ/'
ZZZ12345
hidden 에 주의
regex 매칭에 포함되지 않는 부분은 hidden 으로 출력에 포함되므로 주의해야 합니다.
# 여기서 'AAA' 는 매칭에 포함되지 않은 hidden 이다.
$ echo 'AAA CONFIG_FOO BBB' | sed -E 's/(CONFIG_\w+).*/\1/'
AAA CONFIG_FOO
# hidden 이 생기지 않게 하려면 다음과 같은 방법으로 전체 라인을 매칭을 해야 한다.
$ echo AAA CONFIG_FOO BBB | sed -E 's/.*(CONFIG_\w+).*/\1/'
CONFIG_FOO
# 여기서는 2017 이 hidden 이고 greedy '.*' 에 의해 1000 까지 매칭이 된다.
$ echo '2017-01-19:31:51 15333 37723 - MATCH: 1000 [text]' |
sed -E 's/-.* ([0-9]+) .*/-\1/'
2017-1000
다음은 strace 출력에서 함수 이름을 추출하려고 한것인데요. 출력 결과를 보면 마지막 라인은 표시되지 말아야 하는데 출력이 되고 있습니다.
$ cat some.strace
26074 exit(0) = ?
26074 +++ exited with 0 +++
26073 close(65) = 0
26073 gettid() = 26073
26074 <... madvise resumed> ) = 0
26073 gettid() = 26073
26073 <... futex resumed> ) = -1 EAGAIN (Resource temporarily unavailabl
$ sed -En 's/[0-9]+ (\w+).*/\1/p' some.strace
exit
close
gettid
gettid
26073 <... futex resumed> ) = -EAGAIN
26073 <... futex resumed> ) = - 부분이 hidden 이 되기 때문입니다.
$ sed -En 's/[0-9]+ (\w+).*/XXX\1YYY/p' some.strace
XXXexitYYY
XXXcloseYYY
XXXgettidYYY
XXXgettidYYY
26073 <... futex resumed> ) = -XXXEAGAINYYY
따라서 다음과 같이 앞에 ^ anchor 를 붙여주어야 합니다.
$ sed -En 's/^[0-9]+ (\w+).*/\1/p' some.strace
exit
close
gettid
gettid
예제 1
다음 데이터는 CSV( comma-separated values ) 인데요. 여러 가지 방법을 이용해서 필드의 위치를 변경합니다.
# 2번째 필드와 3번째 필드 바꾸기
# 여기서 매칭이 안되는 111, 444 는 hidden 이다.
$ echo '111,222,333,444' | sed -E 's/,(.*),(.*),/,\2,\1,/'
111,333,222,444
# 4번째 필드를 1번째로, 1,2번째 필드를 마지막으로
# '.*' 가 복수개 이상 사용되면 첫 번째 것이 greedy 가 된다.
# 결과적으로 매칭은 (111,222),(333),(444)
$ echo '111,222,333,444' | sed -E 's/(.*),(.*),(.*)/\3,\2,\1/'
444,333,111,222
# 4번째 필드와 1번째 필드 바꾸기
$ echo '111,222,333,444' | sed -E 's/(.*),(.*),(.*),(.*)/\4,\2,\3,\1/'
444,222,333,111
예제 2
IP 주소는 4 개의 숫자로 이루어지는데 각각 범위가 0 ~ 255 까지입니다.
regex 을 이용해서 IP 주소가 맞는지 확인하는 것입니다.
$ sed -En '/(([0-9]{1,2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([0-9]{1,2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])/p' <<\@
192.168.0.1
127.0.0.1
123.456.789.101 # 456 789 는 IP 주소가 아니다.
10.1.2.4
@
192.168.0.1
127.0.0.1
10.1.2.4
예제 3
다음은 "[숫자 - 숫자]" 형태의 필드에서 첫 번째 숫자만 추출해서 표시합니다.
# 숫자에 소수점이 포함되므로 '[0-9.]' 을 사용
$ echo '10368,"Verizon DSL",DSL,NY,NORTHEAST,-5,-4,"[1.1 - 3.0]","[0.384 - 0.768]"' |
sed -E 's#"\[([0-9.]*)[^"]*"#"\1"#g'
10368,"Verizon DSL",DSL,NY,NORTHEAST,-5,-4,"1.1","0.384"
예제 4
두 번째 double quote 으로 둘러싸인 값을 [ ] 안으로 넣고 각각의 값들을 comma 로 분리하여 double quote 합니다.
# Before
{"name": "john , jane, gordon ,matthew"}
# After
{"name": ["john","jane","gordon","matthew"]}
-------------------------------------------
$ sed -E '
s/"([^"]+)".*"([^"]+)"/"\1": ["\2"]/ # quotes 으로 둘러싸인 첫번째, 두번째값 분리
s/ ?, ?/","/g # comma 로 분리된 각각의 값들을 quote 처리
' file
{"name": ["john","jane","gordon","matthew"]}
예제 5
이번 예제는 ( ) 의 nesting 기능과 .* 의 greedy 한 속성을 이용해서 데이터를 변경합니다.
# Before
//svn.server.address/repos/module1/branches/issue-001-name1
//svn.server.address/repos/module2/branches/issue-002-name2
//svn.server.address/repos/module3/branches/issue-003-name3
$ sed -E 's#\s+(.*/(.*))#svn co \1 \2#' file
# After
svn co //svn.server.address/repos/module1/branches/issue-001-name1 issue-001-name1
svn co //svn.server.address/repos/module2/branches/issue-002-name2 issue-002-name2
svn co //svn.server.address/repos/module3/branches/issue-003-name3 issue-003-name3
Quiz
사용자에게 C/C++ 함수의 원형을 입력받아서 매칭이 존재하는지 확인하는 스크립트를 만들려고 합니다. sed 명령문을 어떻게 작성하면 좋을까요?
C/C++ 함수의 원형에는 regex 에서 사용되는
(,)문자가 존재하므로 ERE 보다는 BRE 로 작성하는것이 좋겠습니다.그리고
*,.,[문자는 BRE, ERE 모두에서 regex 문자로 사용되므로 escape 해줘야 합니다.
# C/C++ 함수의 원형에는 regex 에서 사용되는 ( , ) , [ , * 문자가 존재한다.
int foobar(const char*, int (*) [3])
----------------------------------------------------------
# 사용자가 위의 함수 원형을 입력했다고 가정하고 변수에 대입해서 매칭을 해보겠습니다.
$ input='int foobar(const char*, int (*) [3])'
# sed 명령문을 BRE 로 작성하였지만 매칭이 되지 않는다.
$ echo 'int foobar(const char*, int (*) [3])' | sed -n '/'"$input"'/p'
$
# shell 의 매개변수 확장 기능을 이용해 * 문자를 \* 로 [ 문자를 \[ 로 escape 해 줍니다.
$ input=${input//\*/\\*}
$ input=${input//[/\\[}
$ echo "$input"
int foobar(const char\*, int (\*) \[3])
# 이제 정상적으로 매칭이 되는것을 볼 수 있습니다.
$ echo 'int foobar(const char*, int (*) [3])' | sed -n '/'"$input"'/p'
int foobar(const char*, int (*) [3])