Multiple lines
sed 에 대해서 많은 분들이 잘못 생각하고 있는 것 중에 하나가 sed 는 라인 단위로 처리를 하기 때문에 multiple lines 를 처리하지 못한다는 것입니다. 사실은 그렇지 않고 sed 는 multiple lines 를 처리하는데 필요한 flag 와 여러가지 명령들을 제공합니다.
multi-line 모드
Mflag
pattern space 에 라인을 append 할 수 있는N명령
hold space 에 append 할 수 있는H명령
pattern space 에 있는 내용 중 첫 라인만 프린트하는P명령
pattern space 에 있는 내용 중 첫 라인만 삭제하는D명령
간단히 사용할 수 있는 방법
sed 명령의 -z 옵션을 이용하면 전체 파일 내용을 pattern space 로 한번에 읽어 들일 수 있습니다.
이후에 s 명령을 이용하면 muti-line 을 간단히 처리할 수 있습니다.
이 방법의 단점은 전체 파일을 읽어들이므로 특정 구간에만 변경을 적용할 수 없고
M flag 를 이용한 multi-line 모드를 사용할 수 없습니다.
$ cat sample.txt
This is a cat.
This is a dog.
This is a turtle.
This is a gecko.
This is a parrot.
This is a rabbit.
# turtle, gecko multi-line 삭제
$ sed -z 's#This is a turtle\.\nThis is a gecko\.\n##g' sample.txt
# turtle 단어가 들어있는 라인 바로 다음 라인에 gecko 가 들어있을 경우 삭제
$ sed -z 's#[^\n]*turtle[^\n]*\n[^\n]*gecko[^\n]*\n##g' sample.txt
This is a cat.
This is a dog.
This is a parrot.
This is a rabbit.
# HAMSTER 로 대체
$ sed -z 's#This is a turtle\.\nThis is a gecko\.#THIS IS A HAMSTER.#g' sample.txt
$ sed -z 's#[^\n]*turtle[^\n]*\n[^\n]*gecko[^\n]*#THIS IS A HAMSTER.#g' sample.txt
This is a cat.
This is a dog.
THIS IS A HAMSTER.
This is a parrot.
This is a rabbit.
------------------------------------------------------
# 특정 라인의 위, 아래에 라인을 추가하는 것은 -z 옵션 없이 할 수 있습니다.
# turtle 라인 아래 HAMSTER 추가
$ sed 's/.*turtle.*/&\nTHIS IS A HAMMSTER./' sample.txt
# 또는
$ sed '/turtle/ s/$/\nTHIS IS A HAMMSTER./' sample.txt
This is a cat.
This is a dog.
This is a turtle.
THIS IS A HAMMSTER.
This is a gecko.
This is a parrot.
This is a rabbit.
# turtle 라인 위에 HAMSTER 추가
$ sed 's/.*turtle.*/THIS IS A HAMMSTER.\n&/' sample.txt
# 또는
$ sed '/turtle/ s/^/THIS IS A HAMMSTER.\n/' sample.txt
This is a cat.
This is a dog.
THIS IS A HAMMSTER.
This is a turtle.
This is a gecko.
This is a parrot.
This is a rabbit.
 Substitute
Substitute
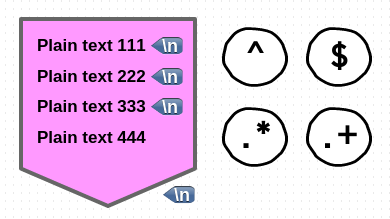
위 그림은 pattern space 에 여러개의 라인이 들어있을 때를 나타내는데요.
sed 는 기본적으로 pattern space 에 있는 데이터를 모두 하나의 라인으로 취급합니다.
그래서 pattern space 에 실질적으로 4개의 라인이 들어있어도 ^ , $ 문자는 각각 전체 데이터의
처음과 끝을 가리키고 s/.*// 명령은 pattern space 에 있는 내용 전체를 삭제합니다.
$ echo -e "111\n222\n333\n444" | sed -En 'N;N;N; s/^/XXX/; s/$/YYY/; p'
# 'g' flag 를 사용해도 마찬가지이다.
$ echo -e "111\n222\n333\n444" | sed -En 'N;N;N; s/^/XXX/g; s/$/YYY/g; p'
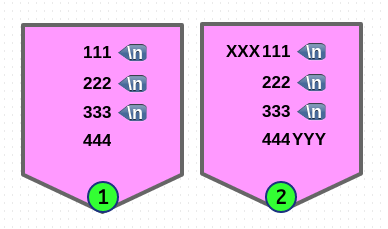
# 's/.*//' 명령은 pattern space 에 있는 내용 전체를 삭제한다.
$ echo -e "111\n222\n333\n444" | sed -En 'N;N;N; s/.*//; p'
Multi-line 모드에서 ^ , $ , .* , .+ 는 특별하게 처리됩니다.
^ , $ 는 각 라인의 처음과 끝을 가리키고 .*, .+ 도 역시 각각의 라인과 매칭을 합니다.
이 4 가지 경우를 제외하고는 Multi-line 모드 라도 default 모드와 차이가 없습니다.
예를 들어서 s/X/Y/3 ( 3번째 매칭에서 X 를 Y 로 변경 ) 같은 명령은 s/X/Y/M3 에서도 같은 결과를 갖습니다.
s 명령에서 사용되는 숫자 나 g flag 은 각각 N 번째 매칭, global 매칭을 의미하는데
Multi-line 모드에서는 다음과 같이 작동합니다.
# 'M' multi-line 모드, '1' 번째 매칭 이므로 첫 번째 라인의 처음과 끝을 가리킵니다.
$ echo -e "111\n222\n333\n444" | sed -En 'N;N;N; s/^/XXX/M1; s/$/YYY/M1; p'
# 매칭 넘버를 적지 않으면 default 값이 1 이므로 'M' 은 'M1' 과 같습니다.
$ echo -e "111\n222\n333\n444" | sed -En 'N;N;N; s/^/XXX/M; s/$/YYY/M; p'
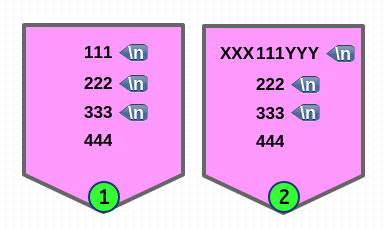
# 'M' multi-line 모드, '2' 번째 매칭 이므로 두 번째 라인의 처음과 끝을 가리킵니다.
$ echo -e "111\n222\n333\n444" | sed -En 'N;N;N; s/^/XXX/M2; s/$/YYY/M2; p'
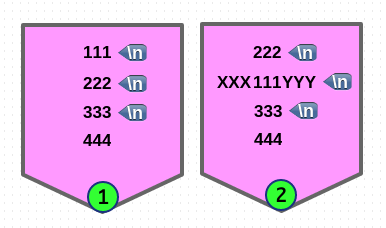
# 'M' multi-line 모드, 'g' 는 global 매칭 이므로 전체 라인의 처음과 끝을 가리킵니다.
$ echo -e "111\n222\n333\n444" | sed -En 'N;N;N; s/^/XXX/Mg; s/$/YYY/Mg; p'
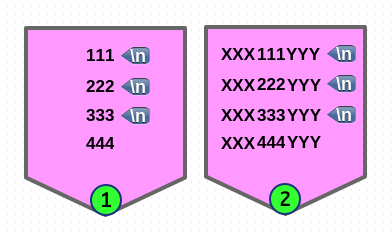
# 'M' multi-line 모드, '3' 은 세 번째 매칭부터, 'g' 는 전부를 가리킵니다.
echo -e "111\n222\n333\n444" | sed -En 'N;N;N; s/^/XXX/M3g; s/$/YYY/M3g; p'
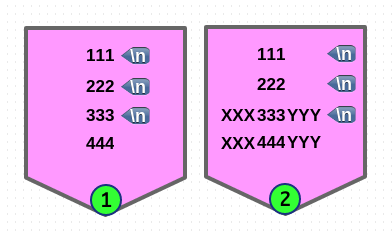
위의 경우는 regex 에서 단순히 ^, $ 문자만 사용했기 때문에 기본적으로
라인 전체가 매칭이 되지만 다음과 같이 라인 중에 일부분만 매칭이 될 수도 있습니다.
# 전체 라인 중에서 2개만 매칭이 되는 경우
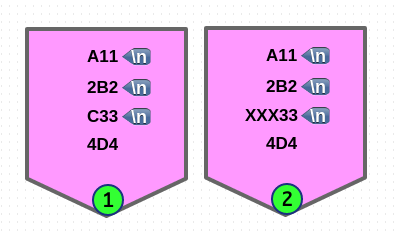
$ echo -e "A11\n2B2\nC33\n4D4" | sed -En 'N;N;N; s/^[A-Z]/XXX/Mg; p'
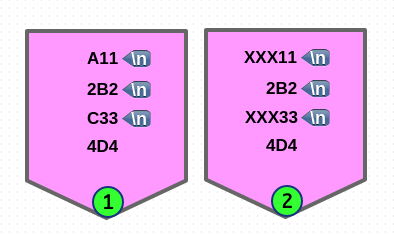
# 'M' multi-line 모드, '2' 번째 매칭 이므로 세 번째 라인이 됩니다.
$ echo -e "A11\n2B2\nC33\n4D4" | sed -En 'N;N;N; s/^[A-Z]/XXX/M2; p'
라인 삭제 방법
Multi-line 모드를 이용하면 손쉽게 원하는 라인을 삭제할 수 있습니다. 이때 라인 개수는 그대로 남겨두고 내용만 삭제할 수도 있고 라인 자체를 삭제할 수도 있습니다.
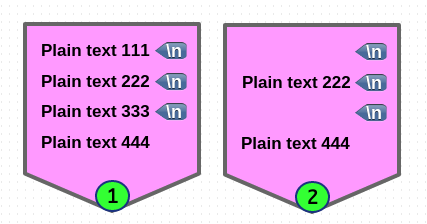
다음은 해당 라인의 내용만 삭제하는 경우입니다.
M flag 의 매칭 넘버 값이 해당 라인을 가리키는 것을 볼수 있습니다.
$ cat file
Plain text 111
Plain text 222
Plain text 333
Plain text 444
# s/.*//M1 명령은 실질적으로 s/[^\n]*// 명령과 같습니다.
# s/.*//M3 명령은 실질적으로 s/[^\n]*//3 명령과 같습니다.
$ sed -En 'N;N;N; s/.*//M1; s/.*//M3p' file
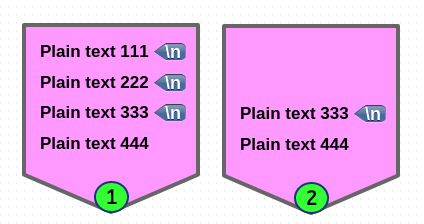
이번에는 라인 자체를 삭제하는 경우로 실행 후에는 라인 개수가 변경됩니다.
그러므로 M1 flag 으로 첫 번째 라인을 삭제한 후 두 번째 라인을 삭제할 때도
동일하게 M1 flag 가 사용된 것을 볼수 있습니다.
# s/.*\n//M1 명령은 실질적으로 s/[^\n]*\n// 명령과 같습니다.
$ sed -En 'N;N;N; s/.*\n//M1; s/.*\n//M1p' file
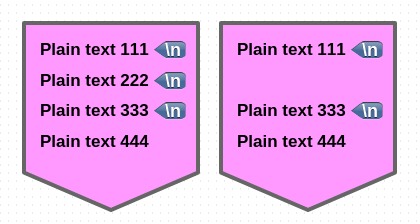
다음은 2번째 매칭 라인을 삭제하는 경우입니다.
# s/.*\n//M2 명령은 실질적으로 s/[^\n]*\n//2 명령과 같습니다.
$ sed -En 'N;N;N; s/.*\n//M2p' file
Addresses
address 지정에 사용되는 /regex/ 에서도 M flag 을 사용할 수 있습니다.
이때 M 은 OR 역할을 합니다.
그러니까 전체 라인 중에서 하나만 매칭이 되어도 true 가 되는 것입니다.
다음과 같은 경우 ^[A-Z] 에 매칭 되는 라인이 3번째에 있기 때문에
M flag 을 사용하지 않고는 ^ 문자로 매칭이 되지 않습니다.
address 에서는
M과 함께숫자나gflag 은 사용되지 않습니다.

# 'CC' 가 전체 데이터의 처음 위치에 있지 않으므로 매칭이 되지 않는다.
$ echo -e "111\n222\nCC3\n444" | sed -En 'N;N;N; /^[A-Z]/p'
# 'M' flag 을 사용하면 매칭이 된다.
$ echo -e "111\n222\nCC3\n444" | sed -En 'N;N;N; /^[A-Z]/Mp'
111
222
CC3
444
Multiple lines 를 다루는 기본 방법
sed 는 stream editor 이므로 한번 라인이 지나가면 다시 사용할 수 없습니다. 그러므로 multiple lines 을 처리하기 위해서는 기본적으로 원하는 만큼의 라인수를 버퍼에 저장하고 있어야 합니다.
다음은 버퍼에 지속해서 2개의 라인을 유지하면서 라인을 프린트하는 방법입니다.
$ cat file
111
222
333
444
555
# 명령 사이클을 시작하면서 pattern space 에 라인 하나를 읽어들였는데
# 또 N 명령을 만났으므로 라인 하나를 더 읽어들여 append 합니다.
# 결과적으로 현재 pattern space 는 2개의 라인이 존재하게 됩니다.
# P 명령은 pattern space 에서 첫 번째 라인만 프린트를 하고 D 명령은 첫 번째 라인만 삭제합니다.
# D 명령은 이어 명령 사이클의 BEGIN 으로 분기합니다. (이때 라인을 읽어들이지 않습니다.)
# 이후 BEGIN 에서 다시 시작하면서 N 명령에 의해 라인이 pattern space 로 append 되므로
# pattern space 에는 항상 2개의 라인이 유지가 됩니다.
# 그런데 여기서 한가지 문제점은 마지막 555 라인이 표시되지 않는 것을 볼수 있습니다.
$ sed -En 'N; P;D' file
111
222
333
444
# 디버깅을 하기 위해 'l' 명령으로 pattern space 를 살펴보면 444 라인이 프린트되는 때는 이미
# pattern space 에 마지막 라인인 555 가 입력되어 있는 것을 볼수 있습니다.
# 444 라인이 P 명령에 의해 프린트되고 D 명령에 의해 삭제된 후 명령 사이클의 BEGIN 으로 가서
# N 명령이 실행되면 N 명령은 기본적으로 다음에 읽어들일 라인이 없으면 exit 하므로 이 부분에서
# 종료가 되는 것입니다. 다시 말해서 555 라인이 P 명령에 의해 표시되기 전에 종료가 됩니다.
# 따라서 N 명령이 마지막 라인에서는 실행되지 못하게 '$!N' 형식의 명령을 사용해야 합니다.
$ sed -En 'N; l; P;D' file
111\n222$
111
222\n333$
222
333\n444$
333
444\n555$
444
# 'N' 명령을 '$!N' 로 수정
$ sed -En '$!N; l; P;D' file
111\n222$
111
222\n333$
222
333\n444$
333
444\n555$
444
555$
555
이번에는 버퍼에 지속해서 3개의 라인을 유지하면서 라인을 프린트해보겠습니다.
# 버퍼에 3개의 라인을 유지하기 위해 '1{$!N}' 를 추가하였습니다.
# '1{$!N}' 명령은 첫 번째 라인이 입력될 때만 실행됩니다.
# 그 이후로는 이어지는 '$!N' 명령에 의해 한 라인씩 append 됩니다.
# '$!N' 명령을 사용하였으므로 마지막 라인까지 모두 정상적으로 프린트되는 것을 볼수 있습니다.
$ sed -En '1{$!N}; $!N; l; P;D' file
111\n222\n333$
111
222\n333\n444$
222
333\n444\n555$
333
444\n555$
444
555$
555
비슷하게 버퍼에 지속해서 4개의 라인을 유지하려면 다음과 같이 하면 됩니다.
$ sed -En '1{$!N; $!N}; $!N; l; P;D' file
111\n222\n333\n444$
111
222\n333\n444\n555$
222
333\n444\n555$
333
444\n555$
444
555$
555
이번에는 실제 데이터 파일을 가지고 수정 작업을 해보겠습니다.
파일 안에는 1번과 같이 3개의 라인이 값을 구성하고 있는데요. 이것을 2번 값으로 변경하겠습니다.
# 1번
...
<servlet-name>
cofaxTools
</servlet-name>
...
# 2번
...
<servlet-class>
org.cofax.cms.CofaxToolsServlet
</servlet-class>
...
--------------------------------
$ sed -E '
1{$!N}
$!N
\#(\s*)<servlet-name>(\s+)cofaxTools(\s+)</servlet-name># {
s##\1<servlet-class>\2org.cofax.cms.CofaxToolsServlet\3</servlet-class>#
}
P; D
' file
--------------------------------
# 다음은 -z 옵션을 사용할 경우
$ sed -Ez 's#(\s*)<servlet-name>(\s+)cofaxTools(\s+)</servlet-name>#'\
'\1<servlet-class>\2org.cofax.cms.CofaxToolsServlet\3</servlet-class>#' file
이번에는 2개의 라인을 유지하는 경우입니다.
아래와 같은 sql 문이 있을 경우 FULLTEXT KEY 라인을 삭제하려고 하는데요.
이때 그냥 해당 라인만 삭제해버리면 앞 라인에 , 가 남아 있기 때문에 sql 문 실행시 오류가 발생합니다.
그래서 , 도 함께 삭제해야 하는데 이때 multiple lines 방법을 이용할 수 있습니다.
CREATE TABLE `table` (
`id` int(10) NOT NULL auto_increment,
`name` varchar(100) NOT NULL default '',
`description` text NOT NULL,
PRIMARY KEY (`id`),
FULLTEXT KEY `full_index` (`name`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
----------------------------------------------
$ sed -En '$!N; s/,\s+FULLTEXT KEY.+// ;P;D' file
CREATE TABLE `table` (
`id` int(10) NOT NULL auto_increment,
`name` varchar(100) NOT NULL default '',
`description` text NOT NULL,
PRIMARY KEY (`id`) <---- ',' 도 함께 제거 되었다.
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
-----------------------------------------------
# -z 옵션을 사용할 경우
$ sed -Ez 's/,\s+FULLTEXT KEY[^\n]+//' file
multiple lines 를 다룰 때 한가지 생각해야 될 부분은
가령 pattern space 에서 3개의 라인을 유지하고 있는데 s 명령에 의해
라인이 1개로 줄어 버리는 경우입니다.
이럴 때는 s 명령이 실행되는 블록에서 $!N 명령을 이용하여 3개의 라인이 되도록
맞추어주어야 합니다.
$ sed -En '
1{$!N}
$!N
/aaa\nbbb\nccc/{
s##xxx# # "s" 명령에 의해 유지하고 있던 3개의 라인이 1개로 줄어듦
$!N # 2번 $!N 명령을 실행하여 3개의 라인으로 맞춥니다.
$!N
}
P;D
' file
이번에는 pattern space 에서 3개의 라인을 유지하는데 s 명령에 의해서
라인이 5개로 늘어나는 경우입니다.
이때는 초과되는 라인을 P 명령으로 프린트하고 M1 명령을 이용해 삭제하여
pattern space 에는 3개의 라인이 유지되도록 합니다.
$ sed -En '
1{$!N}
$!N
/aaa\nbbb\nccc/{ # "s" 명령에 의해 유지하고 있던 3개의 라인이 5개로 늘어남
s##vvv\nwww\nxxx\nyyy\nzzz#
P; s/.*\n//M1 # "P" 명령으로 첫번째 라인 프린트, "M1" 명령으로 첫번째 라인 삭제
P; s/.*\n//M1 # 여기서 "M1" 명령으로 삭제하는 것은 "D" 명령을 이용하면
} # 실행 후 명령 사이클의 BEGIN 으로 분기하기 때문입니다.
P;D
' file
특정 구간에만 변경을 적용하기
다음은 --START-- 와 --END-- 사이의 구간에만 변경을 적용합니다.
$ cat file
111
222
<servlet-name>
cofaxTools
</servlet-name>
333
--START--
444
555
<servlet-name>
cofaxTools
</servlet-name>
666
777
--END--
888
999
.....................................
$ sed -E '
/--START--/,/--END--/ {
/--START--/{$!N}
$!N
s#(\s*)<servlet-name>(\s+)cofaxTools(\s+)</servlet-name>#\
\1<servlet-class>\2org.cofax.cms.CofaxToolsServlet\3</servlet-class>#
P; D
}
' file
############### output ###############
111
222
<servlet-name>
cofaxTools
</servlet-name>
333
--START--
444
555
<servlet-class>
org.cofax.cms.CofaxToolsServlet
</servlet-class>
666
777
--END--
888
999
예제 1
다음과 같이 space 로 분리되는 4개의 필드를 갖는 레코드가 있습니다.
이때 3, 4번 필드 값을 5개 이내 문자로 제한해서 프린트합니다.
꼭 원본 데이터를 있는 그대로 사용해야만 되는 것은 아니고 필요에 따라 수정해서 사용할 수 있습니다.
# 데이터 내용
844388240 920009 XXXX YYYYYYYYYY
844388240 920009 XXXX 1234567890
800450220 910003 AAAAAAAAA BBB
800450220 910003 123456789 BBB
736458376 947883 HHH GG
800450220 910003 AAAAAAAAAAAAA YYYYYYYYYYYYYYY
800450220 910003 1234567890123 123456789012345
-----------------------------------------------
$ sed -E '
s/ /\n/g # multi-line 모드를 활용하기 위해 space 를 newline 으로 변경
s/(.{,5}).*/\1/M3 # 3, 4 번째 매칭 라인의 값에서 앞 5문자만 추출
s/(.{,5}).*/\1/M4
s/\n/ /g # multi-line 모드 작업이 완료되었으므로 newline 을 space 로 변경
' file
844388240 920009 XXXX YYYYY
844388240 920009 XXXX 12345
800450220 910003 AAAAA BBB
800450220 910003 12345 BBB
736458376 947883 HHH GG
800450220 910003 AAAAA YYYYY
800450220 910003 12345 12345
예제 2
공백 라인을 구분자로 하는 레코드입니다.
Device=A 항목을 포함하는 레코드만 프린트합니다.
# 데이터 파일 내용
--START--
Data=asdfasdf
Device=B
Lorem=Ipsum
--START--
Data=asdfasdf
Device=A
Lorem=Ipsum
--START--
Data=asdfasdf
Device=B
--START--
Data=asdfasdf
Device=A
--START--
Data=asdfasdf
Device=C
Lorem=Ipsum
.......................
# pattern space 의 마지막 문자가 newline 이라는 것은 공백 라인이 입력된 것을 의미합니다.
$ sed -n '
/--START--/{
:X
N # 공백 라인이 입력될 때까지 계속해서 pattern space 에 append 합니다.
/\n$/!bX # 입력된 라인이 공백 라인이 아닐 경우 :X 로 분기
/^Device=A/Mp # /^Device=A/ 와 매칭이 되면 pattern space 에 있는 내용을 프린트
}' file
--START--
Data=asdfasdf
Device=A
Lorem=Ipsum
--START--
Data=asdfasdf
Device=A
예제 3
이번 예제는 --START-- 를 만나면 이전 2라인을 포함해서 --END-- 까지의 내용을 프린트합니다.
# 데이터 내용
111
222
333
--START--
444
555
--END--
AAA
BBB
CCC
DDD
--START--
EEE
--END--
FFF
GGG
...............
# /XXX[^\n]*$/ 형식은 pattern space 의 마지막 라인에 XXX 가 있는지 매칭할때 사용하는 방법입니다.
$ sed -En '
# --START-- 와 매칭 되면 이전 2라인을 프린트하기 위해
1{:X N;N} # pattern space 의 라인을 3개로 유지합니다.
/--START--[^\n]*$/ { # 마지막 라인이 --START-- 와 매칭 되면
:Y
N # 라인을 하나 더 읽어 들이고
/--END--[^\n]*$/!bY # 마지막 라인이 --END-- 와 매칭이 되는지 체크합니다.
# 매칭이 안되면 다시 :Y 로 분기하여 `N` 명령에 의해
# 다음 라인을 읽어 들입니다.
p # 매칭이 되면 현재 pattern space 내용을 프린트하고
n # `n` 명령으로 현재 pattern space 의 내용을 새로 읽어들인
bX # 라인으로 overwrite 하고 3개의 라인을 맞추기 위해 :X 로 분기
}
N;D # --START-- 와 매칭이 안될 경우 다음 라인을 읽어들여 append 하고
# `D` 명령으로 첫 번째 라인을 삭제한 후 명령 사이클의 BEGIN 으로
# 분기합니다.
' file
222
333
--START--
444
555
--END--
CCC
DDD
--START--
EEE
--END--
예제 4
다음 예제는 forall 라인을 goal 라인 아래로 위치 시키는 것입니다.
s 명령에서 사용된 regex 에서 첫 라인, 중간 라인들, 마지막 라인을 분리하는 방법을
주의깊게 보세요
# 데이터 내용
goal identifier statement
let statement 1
let statement 2
forall statement
other statements
$ sed -E '/goal/{
:X
N
/forall[^\n]*$/!bX
s#^([^\n]*)(.*)(\n[^\n]*)$#\1\3\2#
}' file
goal identifier statement
forall statement
let statement 1
let statement 2
other statements
Quiz
파일 내용 중에서 마우스로 선택한 영역을 간단히 다른 내용으로 변경하려면 어떻게 할까요?
이때는 복사한 내용을 먼저 here document 를 이용해 변수에 저장하고, sed 명령 실행시 오류가 생기는 것을 방지하고 정상적으로 처리되기 위해 필요한 escape 처리를 해주어야 합니다. 다음은 변수 AA 내용을 BB 내용으로 변경하는 예입니다.
# copy 한 내용을 here document 을 이용해 변수에 대입합니다.
AA=$( cat <<\EOF
$('#exampleModal').on('show.bs.modal', function (event) {
var button = $(event.relatedTarget) // Button that ....
var recipient = button.data('whatever') // Extract info ....
var modal = $(this)
modal.find('.modal-title').text("New message to " + recipient)
modal.find('.modal-body input').val(recipient)
})
EOF
)
BB=$( cat <<\EOF
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-1234567');
</script>
EOF
)
# 변경하고자 하는 변수 AA 의 내용은 's' 명령의 왼쪽( regex 를 작성하는 곳 ) 에
# 위치하게 되므로 내용중에 regex 메타문자가 포함될 경우 escape 해야 합니다.
AA=$( echo "$AA" | sed -z -e 's#\([][^$*\.#]\)#\\\1#g' -e 's#\n#\\n#g' )
# BB 변수의 내용도 sed 명령문에서 문제가 생기지 않도록 escape 처리합니다.
BB=$( echo "$BB" | sed -z -e 's#\([&\#]\)#\\\1#g' -e 's#\n#\\n#g' )
# sed 명령은 디폴트인 basic regular expression 으로 실행합니다.
sed -z -i "s#${AA}#${BB}#g" *.html